




Indice de Contenido
Asistentes de voz (Siri)
- ¿Cómo funciona Siri?
- ¿Cuál es la historia del desarrollo de Siri?
Samantha: ¿Sabes lo que es interesante? Antes me preocupaba mucho no tener un cuerpo, pero ahora me encanta. Estoy creciendo de una manera que no podría si tuviera una forma física. Quiero decir, no estoy limitada, puedo estar en cualquier lugar y en cualquier lugar al mismo tiempo. No estoy atada al tiempo y al espacio de una manera que estaría si estuviera atrapado en un cuerpo que inevitablemente va a morir.
— Her (2013)
Los asistentes de voz son cada vez más omnipresentes. Los altavoces inteligentes se hicieron populares después de que Amazon presentara Echo, un altavoz con Alexa como asistente de voz, en noviembre de 2014. Para 2017, decenas de millones de altavoces inteligentes estaban en los hogares de la gente, y cada uno de ellos tenía la voz como interfaz principal. Los asistentes de voz no solo están presentes en los altavoces inteligentes, sino también en todos los teléfonos inteligentes. El más conocido, Siri, alimenta el iPhone.
La impresión debut de Siri de Apple, el primer asistente de voz desplegado en el mercado masivo, se produjo durante un evento mediático el 4 de octubre de 2011. Phil Schiller, vicepresidente sénior de marketing de Apple, presentó Siri mostrando todas sus capacidades, como mirar el pronóstico del tiempo, poner una alarma y revisar el mercado de valores. Ese evento fue en realidad la segunda presentación de Siri. Cuando se lanzó por primera vez, Siri era una aplicación independiente creada por Siri, Inc. Apple compró la tecnología por 200 millones de dólares en abril de 2010. *
Siri fue una rama de un proyecto del Centro Internacional de Inteligencia Artificial de SRI. En 2003, DARPA dirigió un esfuerzo de 5 años y 500 personas para construir un asistente virtual, invirtiendo un total de 150 millones de dólares. En ese momento, CALO, asistente cognitivo que aprende y organiza, era el programa de IA más grande de la historia. Adam Cheyer fue investigador en SRI para el proyecto CALO, ensamblando todas las piezas producidas por los diferentes laboratorios de investigación en un solo asistente. La versión que Cheyer ayudó a construir, también llamada CALO en ese momento, todavía estaba en la etapa de prototipo y no estaba lista para su instalación en los dispositivos de la gente. Cheyer estaba en una posición privilegiada para entender cómo funcionaba CALO de principio a fin.
Cheyer dividió su tiempo trabajando en SRI como investigador y ayudando al programa Vanguard de SRI. Vanguard ayudó a empresas, como Motorola y Deutsche Telekom, a probar el futuro de un nuevo gadget llamado teléfono inteligente. Cheyer desarrolló su propio prototipo de asistente virtual, más limitado que CALO pero mejor para satisfacer las necesidades de Vanguard. El prototipo impresionó al gerente general de Motorola, Dag Kittlaus, quien sin éxito intentó persuadir a Motorola para que usara la tecnología de Vanguard. Renunció y se unió a SRI como empresario residente. Poco después, Cheyer, Kittlaus y Tom Gruber comenzaron Siri, Inc. Su empresa tenía la ventaja de poder utilizar la tecnología de CALO. Según una ley aprobada por el Congreso en 1980, la organización sin fines de lucro SRI podría otorgar a Siri, Inc. esos derechos a cambio de algunas de sus ganancias. Por lo tanto, SRI licenció la tecnología a cambio de una participación en la nueva empresa.
En términos generales, la tecnología de Siri tenía cuatro partes. El reconocimiento de voz tuvo lugar cuando hablaste con Siri. El componente del lenguaje natural captó lo que dijiste. La siguiente parte de la ecuación fue la siguiente parte de la solicitud. El elemento final era que Siri respondiera. *
Para el reconocimiento de voz, Siri utilizó un enfoque completamente diferente al de otras tecnologías en ese momento. El método tradicional, tal como se utilizó con IBM Watson, identificó los conceptos lingüísticos en una oración, como el sujeto, el verbo y el objeto, y basándose en ellos, trató de entender lo que estas piezas significaban juntas.
En su lugar, el equipo de Siri modeló objetos del mundo real. Cuando se le dijo: “Quiero ver un thriller”, Siri reconoció la palabra “thriller” como un género cinematográfico e invocó películas en lugar de analizar cómo el sujeto se conectaba con el verbo u objeto. Siri mapeó cada pregunta a un dominio de acciones potenciales y luego eligió la que parecía más probable en función de la relación entre los conceptos del mundo real. Por ejemplo, si dijera: “¿A qué hora cierra el McDonald’s más cercano?” Siri mapeó esta pregunta al género de los lugareños, encontró el McDonald’s más cercano a la ubicación actual y preguntó la hora de cierre. Siri respondió con la respuesta.
Siri también empleó algunos trucos adicionales. En un vestíbulo ruidoso, una solicitud de la “cafetería más cerrada” podría sonar como “llamada más cerrada Felicia”, pero Siri sabe que “más cerca” caracteriza un lugar en lugar de una persona, por lo que indujo que la pregunta probablemente estaba relacionada con un lugar y trató de entender la esencia de la oración sin entender cada palabra. Al principio, los creadores de Siri no vieron prácticamente ningún límite en las tareas rutinarias que el asistente podía automatizar, pero también sabían que su asistente solo tendría éxito si era inteligente y divertido interactuar con él. Así que programaron respuestas divertidas a preguntas poco convencionales. Por ejemplo, si le preguntas a Siri: “Cuéntame un chiste”, una de las respuestas es: “El pasado, el presente y el futuro entraron en un bar. Estaba tenso”.
Tres semanas después del lanzamiento de Siri en la App Store, Kittlaus recibió una llamada personal de Steve Jobs, el tardío CEO de Apple, que quería comprar la empresa e integrar Siri directamente en el iPhone. La creación de una interfaz de voz era un área de interés para Jobs, y el equipo de Kittlaus había descifrado el código. Siri, Inc. y Apple unieron fuerzas y lanzaron Siri exclusivamente en el iPhone. Y como resultado, casi todos los dispositivos de consumo conectados a Internet hoy en día integran un asistente de voz o pueden interactuar con uno.
Aunque Apple fue la primera gran empresa tecnológica en integrar un asistente inteligente en su sistema operativo telefónico, otros sistemas se alcanzaron rápidamente y superaron las capacidades de Siri. * Alexa de Amazon apareció por primera vez en 2014, y el Asistente de Google lo siguió en 2016. Estos recién llegados ofrecen más funciones y un mejor software de reconocimiento de voz. Por ejemplo, los nuevos altavoces de Google Home pueden reconocer a diferentes personas por el sonido de sus voces. Si una persona dice: “Ok Google, llama a mi padre”, el dispositivo sabe que debe buscar los contactos de la persona que llama al dispositivo. Google y Alexa también han hecho más con personas ajenas para trabajar en su plataforma. Los desarrolladores han desarrollado más de 25 000 habilidades de Alexa, y el asistente de Amazon se está integrando en coches, televisores y electrodomésticos.
Más recientemente, Apple se está poniendo al día con sus competidores. Hicieron la transición del modelo detrás de su sistema de reconocimiento de voz a una red neuronal en 2014. * Además, Siri ahora interpreta los comandos de manera más flexible. Por ejemplo, si le digo a Siri: “Enviar a Jane 20 $ con Square Cash”, la pantalla muestra el texto que refleja esta solicitud. O, si alguien dice: “Dispara 20 dólares a mi esposa”, ocurre el mismo resultado. En 2017, Apple introdujo una forma de que Siri aprendiera de sus errores añadiendo una capa de aprendizaje por refuerzo. * Y en 2018, creó una plataforma para que los usuarios definieran accesos directos, permitiendo un conjunto personalizado de comandos. * Por ejemplo, un usuario puede crear el comando “Enciende el estado de ánimo romántico” y configurar Siri para que encienda las luces inteligentes en un cierto color y reproduzca música romántica. Todavía hay lagunas, pero las capacidades de Siri siguen aumentando.
EL CEREBRO DE UN ASISTENTE DE VOZ
A un nivel alto, el cerebro de un asistente de voz se divide en algunas tareas principales:*
- [Opcional] Activa la detección de comandos para reconocer frases como “Oye Siri” o “Oye Google” para que el dispositivo escuche el discurso que lo sigue;
- Reconocimiento automático de voz para transcribir el habla humana en texto;
- Procesamiento del lenguaje natural para analizar el texto mediante el etiquetado de voz y el fragmentación de frases de sustantivo;
- Análisis de preguntas e intenciones para analizar el texto analizado, detectando comandos y acciones del usuario como “programar una reunión” o “configurar mi alarma”;
- Tecnologías de mashup de datos para interactuar con servicios web de terceros, como OpenTable o Wolfram|Alpha, para realizar acciones, ejecutar búsquedas y responder preguntas;
- transformaciones de datos para convertir la producción de servicios web de terceros de nuevo en texto en lenguaje natural, como “el informe meteorológico de hoy” en “El tiempo estará soleado hoy”; y
- Por último, técnicas de texto a voz para convertir el texto en voz sintetizada que el asistente de voz responde al usuario.
El primer paso en el iPhone utiliza una red neuronal que detecta la frase “Oye Siri”. * Este paso es un proceso de dos pasos. El primer paso pasa por un pequeño procesador auxiliar de baja potencia en el teléfono o el altavoz. La voz pasa a través de una simple red neuronal que intenta identificar si el sonido es de hecho “Oye Siri”. Después de este primer paso, la voz va al procesador principal que ejecuta una red neuronal más compleja. El segundo paso consiste en traducir el discurso a texto. El habla es una forma de onda codificada como un montón de bits (números). Para traducirlo a texto, Apple entrenó una red neuronal con datos que tienen voz como entrada y el texto correspondiente a ese habla como salida.
Con la excepción de los servicios de terceros, todos los pasos del proceso utilizan la red aneural. Sin embargo, las reglas para interactuar con estas aplicaciones externas requieren código escrito a mano porque cada servicio proporciona una interfaz específica y cierta información. Por ejemplo, Foursquare proporciona datos de empresas como restaurantes, bares y cafeterías. Solo puede devolver información sobre esos negocios. Si el asistente de voz necesita averiguar algo más, como el clima para hoy o mañana, debe obtener información de weather.com o un servicio similar. Al combinar estos pasos, Siri y otros asistentes de voz ayudan a las personas todos los días en tareas como configurar la alarma para el día siguiente y obtener pronósticos meteorológicos.
IA en medicina
- ¿Cómo puede el aprendizaje automático ayudar a la radiología?
- ¿Cómo puede el aprendizaje automático ayudar a detectar el cáncer?
- ¿Qué es una biopsia líquida?
- ¿Qué es AlphaFold?
¿Cómo funciona AlphaFold?
Usaré el tratamiento para ayudar a los enfermos de acuerdo con mi capacidad y juicio, pero nunca con vistas a lesiones y irregularidades.Juramento hipocrático
SEBASTIAN THRUN
Sebastian Thrun, que creció en Alemania, era conocido internacionalmente por su trabajo con sistemas robóticos y sus contribuciones a las técnicas probabilísticas. En 2005, Thrun, un profesor de Stanford, dirigió el equipo que ganó el DARPA Grand Challenge para coches autónomos. Durante un año sabático, se unió a Google y co-desarrollado Google Street View y comenzó Google X. Cofundó Udacity, una escuela en línea con fines de lucro, y es el actual CEO de Kitty Hawk Corporation. Pero en 2017, se sintió atraído por el campo de la medicina. Tenía 49 años, la misma edad que su madre, Kristin (Grüner) Thrun, estaba a su muerte. Kristin, como la mayoría de los pacientes con cáncer, no tenía síntomas al principio. Para cuando fue al médico, su cáncer ya había hecho metástasis, extendiéndose a sus otros órganos. Después de eso, Thrun se obsesionó con la idea de detectar el cáncer en sus primeras etapas, cuando los médicos pueden extirparlo.
Los primeros esfuerzos para automatizar el diagnóstico se parecían al conocimiento de los libros de texto. En el caso de los electrocardiogramas (ECG o ECG), que muestran la actividad eléctrica del corazón como líneas en una pantalla, estos programas trataron de identificar formas de onda características asociadas con diferentes condiciones como la fibrilación auricular o un bloqueo de un vaso sanguíneo. La técnica siguió el camino de los sistemas expertos específicos del dominio de la década de 1980.
En mamografía, los médicos utilizaron el mismo método para la detección del cáncer de mama. El software marcó un área que se ajustaba a una determinada condición y marcaba el área como sospechosa para que los radiólogos la revisaran. Estos sistemas no aprendieron con el tiempo: después de ver miles de radiografías, el sistema no fue mejor para clasificarlas. En 2007, un estudio comparó la precisión de la mamografía antes y después de la implementación de esta tecnología. Los resultados mostraron que después de la mamografía asistida, se introdujo la tasa de biopsias aumentó y la detección de cánceres de mama pequeños e invasivos disminuyó.
Thrun sabía que podía superar a estos algoritmos de diagnóstico de primera generación utilizando el aprendizaje profundo en lugar de algoritmos basados en reglas. Con dos antiguos estudiantes de Stanford, comenzó a explorar la clase más común de cáncer de piel, el carcinoma de queratinocitos y el melanoma, el tipo más peligroso de cáncer de piel. Primero, tuvieron que reunir un gran número de imágenes para identificar la enfermedad. Encontraron 18 repositorios en línea de imágenes de lesiones cutáneas que ya estaban clasificadas por dermatólogos. Estos datos contenían alrededor de 130 000 fotos de acné, erupciones, picaduras de insectos y cánceres. De esas imágenes, 2000 lesiones fueron biopsiadas e identificadas con los tipos de cáncer que estaba buscando, lo que significa que habían sido diagnosticadas con casi certeza.

El equipo de Thrun ejecutó su software de aprendizaje profundo para clasificar los datos y luego comprobó si realmente clasificaban las imágenes correctamente. utilizaron tres categorías: lesiones benignas, lesiones malignas y crecimientos no cancerosos. El equipo comenzó con una red poco capacitada, pero no funcionó tan bien. Por lo tanto, utilizaron una red neuronal ya entrenada para clasificar imágenes, y aprendió más rápido y mejor. El sistema era correcto el 77 % de las veces. A modo de comparación, dos dermatólogos certificados probaron las mismas muestras, y solo tuvieron éxito el 66 % del tiempo.
Luego, ampliaron el estudio a 25 dermatólogos y utilizaron un conjunto de pruebas estándar de oro con alrededor de 2.000 imágenes. En casi todas las pruebas, el programa informático superó a los médicos. Thrun demostró que las técnicas de aprendizaje profundo podrían diagnosticar el cáncer de piel mejor que la mayoría de los médicos.
APRENDIZAJE AUTOMÁTICO EN RADIOLOGÍA
Thrun no es el único que utiliza el aprendizaje profundo para ayudar a avanzar en el campo de la medicina. Andrew Ng, profesor adjunto de la Universidad de Stanford y fundador de Google Brain, dirige una empresa, DeepLearning.AI, que imparte cursos de IA en línea. Su empresa también ha demostrado que los algoritmos de aprendizaje profundo pueden identificar las arritmias de un electrocardiograma mejor que los expertos. * En la misma línea, el Apple Watch 4 introdujo una función que realiza un escaneo de ECG. Anteriormente, este era un examen caro, por lo que proporcionar a millones de personas una prueba gratuita es importante para la sociedad.
Ng también creó software utilizando el aprendizaje profundo para diagnosticar la neumonía mejor que el radiólogo promedio. * La detección temprana de la neumonía puede prevenir algunas de las 50.000 muertes que la enfermedad causa en los EE. UU. cada año. La neumonía es la mayor causa infecciosa de muerte de los niños en todo el mundo, matando a casi un millón de niños menores de cinco años en 2015. *
Los sistemas de aprendizaje profundo para imágenes de mamas y cardíacas están disponibles comercialmente*, pero no están ejecutando algoritmos de aprendizaje profundo, lo que podría mejorar en gran medida la detección.Geoffrey Hinton, uno de los creadores del aprendizaje profundo, dijo en una entrevista con The New Yorker: “Es completamente obvio que en cinco años el aprendizaje profundo le irá mejor que a los radiólogos. … Podrían ser diez años. Dije esto en un hospital. No fue muy bien”. * Cree que los algoritmos de aprendizaje profundo también se utilizarán para ayudar, y posiblemente incluso reemplazar, a los radiorólogos que leen rayos X, tomografías computarizadas y resonancias magnéticas. A Hinton le apasiona usar el aprendizaje profundo para ayudar a diagnosticar a los pacientes porque a su esposa le diagnosticar cáncer de páncreas avanzado. Más tarde, a su hijo le diagnosticaron melanoma, pero después de una biopsia, resultó ser un carcinoma de células basales, un cáncer mucho menos grave
LUCHAR CONTRA EL CÁNCER CON UN APRENDIZAJE PROFUNDO
El cáncer sigue siendo un problema importante para la sociedad. En 2018, alrededor de 1,7 millones de personas en los EE. UU. fueron diagnosticadas con cáncer, y 600.000 personas murieron por él. Existen muchos medicamentos para cada tipo de cáncer, y algunos cánceres incluso tienen más de uno. La tasa de supervivencia a cinco años para muchos cánceres ha aumentado drásticamente en los últimos años, alcanzando entre el 80 % y el 100 % en algunos casos, con cirugía y tratamientos farmacológicos. Pero cuanto antes se detecte el cáncer, mayor será la probabilidad de supervivencia. La clave es prevenir la propagación del cáncer a otros órganos y áreas del cuerpo. El problema es que diagnosticar el cáncer es problemático. Muchos de los métodos de detección no tienen una alta precisión. Algunas mujeres jóvenes desaprueban las mamografías debido a los muchos falsos positivos, que crean preocupación y estrés innecesarios.
Para aumentar las tasas de supervivencia, es extremadamente importante detectar el cáncer lo antes posible, pero encontrar un método asequible es difícil. El proceso actual generalmente implica que los médicos examinen a los pacientes con diferentes técnicas, incluida la comprobación de su piel para ver patrones o pruebas como el examen rectal digital. Dependiendo de los síntomas y el tipo de cáncer, el siguiente paso puede implicar una biopsia del área afectada, extrayendo el tejido tumoral. Desafortunadamente, los pacientes pueden tener células cancerosas que aún no se han propagado, lo que hace que la detección sea aún más difícil. Y, una biopsia suele ser un procedimiento peligroso y costoso. Alrededor del 14 % de los pacientes que se someten a una biopsia pulmonar sufren un colapso pulmonar. *
Freenome, una startup fundada en Silicon Valley, está tratando de detectar el cáncer desde el principio utilizando una nueva técnica llamada biopsia líquida.* Esta prueba secuencia el ADN de unas pocas gotas de sangre. El freenome utiliza ADN libre de células, que son fragmentos de ADN que flotan libremente en la sangre de las personas, para ayudar a diagnosticar a los pacientes con cáncer: el nombre del Freenome proviene de acortar el “geno libre de células”. El ADN libre de células muta cada 20 minutos, lo que lo hace único. El genoma de las personas cambia con el tiempo, y el cáncer no heretado proviene de mutaciones e inestabilidades genómicas que se acumulan con el tiempo. El ADN libre de células fluye a través del torrente sanguíneo, y fragmentos de células cancerosas en un área pueden indicar cáncer en otra región del cuerpo.*
El enfoque del freenome es buscar varios cambios en el ADN libre de células. En lugar de mirar solo el ADN de las células tumorales, Freenome ha aprendido a decodificar señales complejas procedentes de otras células del sistema inmunitario que cambian debido a un tumor en otro lugar. Su tecnología busca los cambios en el ADN a lo largo del tiempo para ver si hay un cambio significativo en comparación con una línea de base. Sin embargo, es difícil detectar el cáncer basándose en cambios codificados en el ADN de alguien. Hay alrededor de 3 mil millones de bases en el ADN, lo que lleva a un total de31,000,000,000 ≈ 10477,121,254posibles genomas. Por lo tanto, averiguar si una mutación en uno de estos genes es causada por otra célula que tiene cáncer es extremadamente difícil. Utilizando el aprendizaje profundo, el sistema de Freenome identifica las partes relevantes del ADN que un médico o investigador no sería capaz de reconocer. ¿Quién podría haber imaginado que el aprendizaje profundo desempeñaría un papel tan integral en la identificación del cáncer? Espero que esta tecnología finalmente conduzca a la cura del cáncer.
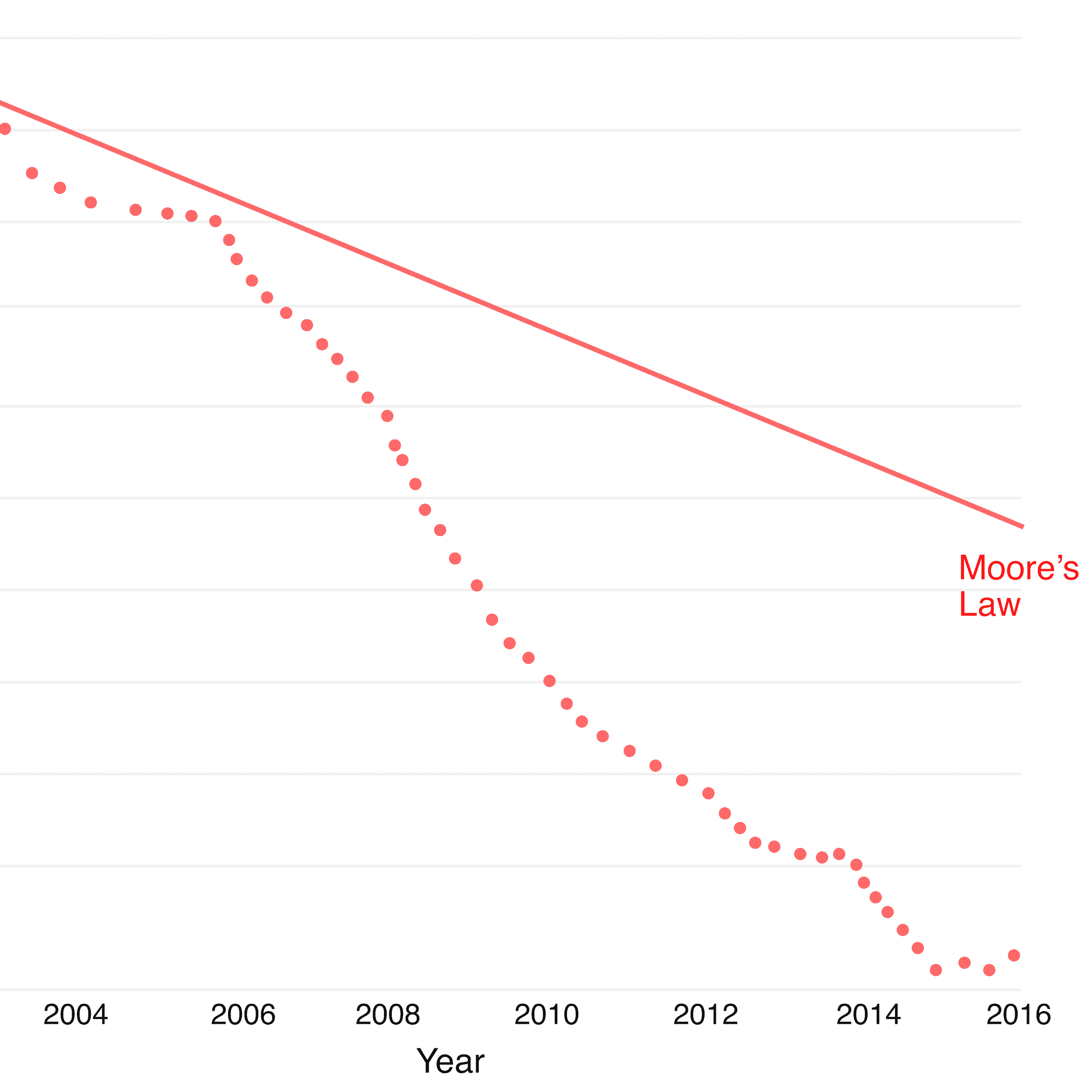
La primera parte del problema consiste en comprobar el ADN de las personas con un simple análisis de sangre. Si bien extraer la sangre es sencillo, la prueba ha sido extremadamente cara de llevar a cabo. Pero con el tiempo, la secuenciación del genoma se ha vuelto cada vez más barata. En 2001, el costo por genoma secuenciado era del orden de 100 millones de dólares, pero en 2020, el precio ha disminuido a solo 1.000 dólares. * Esta tendencia no muestra signos de desaceleración. Si el precio continúa siguiendo la curva, será común que los pacientes se secuencian su genoma por unos pocos dólares. * Puede parecer ficción ahora, pero en unos pocos años, podríamos detectar el cáncer desde el principio con solo unas pocas gotas de sangre.
PLEGADO DE PROTEÍNAS
Las proteínas son moléculas grandes y complejas que son esenciales para mantener la vida. Los humanos los necesitan para todo, como sentir luz y convertir los alimentos en energía. Los genes se traducen en aminoácidos, que se convierten en proteínas. Pero cada proteína tiene una estructura 3D diferente, lo que determina lo que puede hacer. Algunos tienen una forma Y, mientras que otros tienen una forma circular. Por lo tanto, identificar la estructura 3D de una proteína, dada su secuencia genética, es de extrema importancia para los científicos porque puede ayudarles a determinar lo que hace cada proteína. Distinguir cómo se ve la estructura 3D de una proteína, que está determinada por cómo actúan las fuerzas entre los aminoácidos, es un problema inmensamente complejo conocido como problema de plegamiento de proteínas. Contar todas las configuraciones posibles de una proteína llevaría más tiempo que la edad del universo.
Pero DeepMind abordó este problema con AlphaFold* presentándolo a CASP, una evaluación bienal de los métodos de predicción de la estructura de proteínas. CASP significa Evaluación Crítica de Técnicas para la Predicción de la Estructura de las Proteínas. * DeepMind entrenó su sistema de aprendizaje profundo utilizando datos altamente disponibles que asignan secuencias genómicas a las proteínas correspondientes con sus estructuras 3D.
Dada una secuencia génica, es fácil asignarla a la secuencia de aminoácidos dentro de la proteína generada. Con esa secuencia, DeepMind creó redes neuronales de dos capas múltiples. Uno predijo la distancia de cada par de aminoácidos en esa proteína. La segunda red neuronal predijo los ángulos entre los enlaces químicos que conectan estos aminoácidos. Por lo tanto, estas dos redes predijeron qué estructuras 3D de las proteínas serían las más cercanas a la que generarían estos genes. Dada la estructura proteica más cercana, utilizó un proceso iterativo y reemplazó algunas de las estructuras proteicas por otras nuevas creadas utilizando una red adversaria generativa basada en la secuencia génica. * Si la estructura proteica recién creada tenía una puntuación más alta que la estructura proteica anterior, entonces esa parte de la proteína fue reemplazada. Con esta técnica, AlphaFold determinó las estructuras proteicas mucho mejor que el siguiente mejor concursante de la competencia, así como todos los algoritmos anteriores.
LA PROLONGACIÓN DE LA VIDA
PRECAUCIÓNPero con esta nueva tecnología, debemos volver a una discusión sobre la ética. Mientras los humanos han habitado esta Tierra, hemos buscado la fuente de la juventud, la inmortalidad. Mientras que algunas personas ven la calidad de vida como lo más importante, otras ven la longevidad como clave. Elizabeth Holmes y su papel en el laboratorio de Theranos demuestran claramente el riesgo de aceptar ciegamente la tecnología antes de ser probada científicamente. Personalmente, creo que la IA juega un papel vital tanto en el aumento de la longevidad como en la calidad de vida, pero debemos mantener pruebas estrictas y el cumplimiento de los principios científicos. *
IA y espacio
- ¿Cómo puede el aprendizaje profundo ayudar a predecir los rendimientos de los cultivos?
- ¿Cómo puede el aprendizaje profundo ayudar a encontrar planetas?
La imaginación a menudo nos llevará a mundos que nunca lo fueron. Pero sin él no vamos a ninguna parte.Carl Sagan*
PREDICCIÓN DE CULTIVOS
Sin embargo, para analizar estas imágenes, los datos necesitan una clasificación adecuada. Para resolver este problema, Descartes Labs, una empresa de análisis de datos, une imágenes diarias de satélite en un mapa en vivo de la superficie del planeta y edita automáticamente cualquier cubierta de nubes. * Con estas imágenes limpias, utilizan el aprendizaje profundo para predecir con mayor precisión que el gobierno el porcentaje de granjas en los Estados Unidos que cultivarán soja o maíz. * Dado que la producción de maíz es un negocio que vale alrededor de 67 mil millones de dólares, esta información es extremadamente útil para los pronosticadores económicos de las empresas agroindustriales que necesitan saber cómo predecir los productos estacionales. El Departamento de Agricultura de los Estados Unidos (USDA) proporcionó el punto de referencia anterior para el uso de la tierra, pero esa técnica utilizó datos de un año cuando se publicaron.
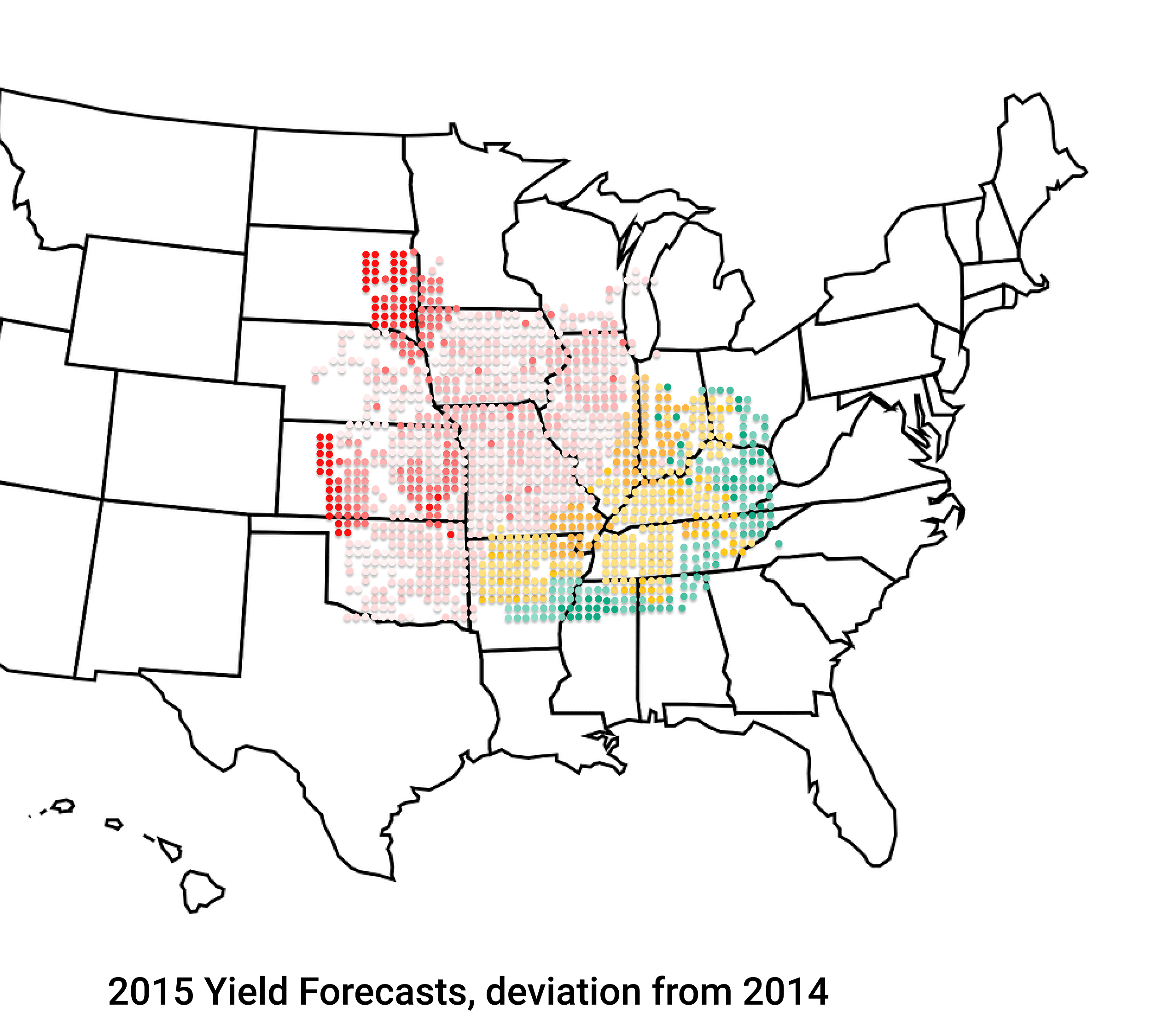
En 2015, por ejemplo, la FDA predijo una producción nacional de 13.53 mil millones de bushels de maíz. Descartes Labs, sin embargo, pronosticó 13.34 millones de bushels, como se ve en la imagen de arriba. Descartes Labs utilizó una vista casi real para visualizar y medir desarrollos como inundaciones o cambios en las condiciones de los cultivos. Utilizando el aprendizaje profundo, la compañía explotó los datos de la NASA y otras fuentes y los analizó más rápido que el gobierno, prediciendo los rendimientos futuros basados en los datos recopilados.
El gobierno gastó un sinfín de recursos encuestando a los agricultores de todo el país para identificar los cultivos existentes para cada producto con el fin de predecir el rendimiento futuro. Descartes Labs eliminó esta carga, reduciendo el costo de predecir la cosecha. Entrenaron su algoritmo, que extrae información valiosa de las imágenes satelitales, para predecir futuros cultivos de maíz en función del color y la apariencia de las plantas en el campo.
Y esto es solo el comienzo de la extracción de información de imágenes de satélite. Otras startups están estudiando diferentes casos de uso. Por ejemplo, Orbital Insight utiliza el aprendizaje profundo para examinar las infraestructuras, como los estacionamientos y los contenedores de almacenamiento de petróleo, para predecir y revelar datos económicos importantes.
ENCONTRAR PLANETAS
El aprendizaje profundo no solo ha sido útil para analizar la Tierra, sino también para descubrir lo que hay en el universo. Con ocho planetas orbitando el Sol, nuestro sistema solar tenía el título de la mayoría de los planetas alrededor de una estrella en la Vía Láctea. Pero en diciembre de 2017, la NASA y Google descubrieron un nuevo planeta orbitando una estrella lejana, Kepler 90, lo que también eleva el número total de planetas para esa estrella a ocho. Ese descubrimiento no fue una hazaña fácil teniendo en cuenta que la estrella se encuentra a más de 2.500 años luz de nosotros.
Usando un telescopio que ha estado buscando planetas desde 2009, el Telescopio Kepler de la NASA, los científicos han descubierto miles de planetas. La diferencia de hoy es que en lugar de que los astrofísicos encuentren manualmente nuevos descubrimientos, las redes neuronales hacen el trabajo.
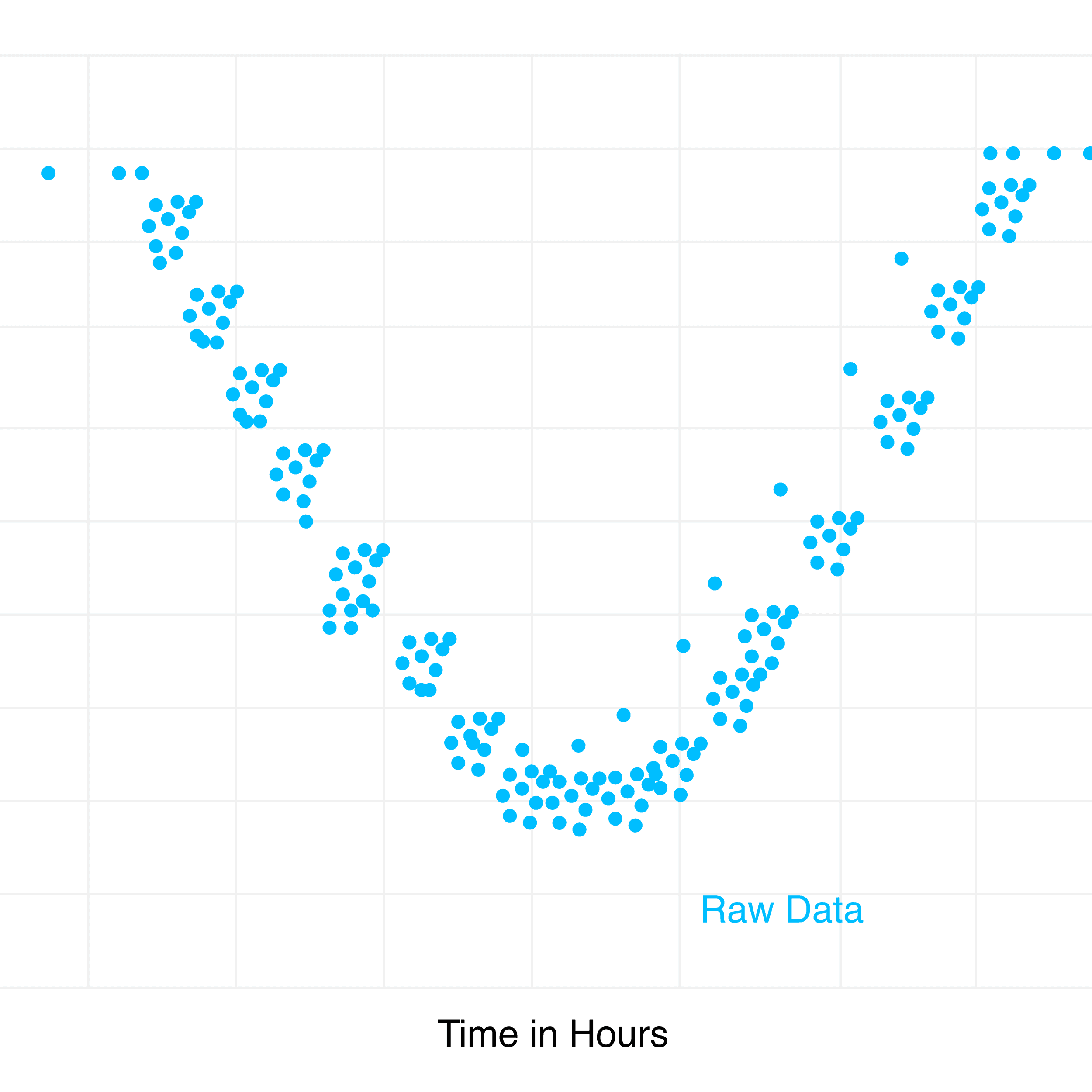
El telescopio Kepler de la NASA muestra datos con el brillo de una estrella, basados en imágenes tomadas del telescopio. Un planeta se puede detectar en función del cambio en el brillo de la estrella. Cuando un planeta rodea una estrella y pasa entre la estrella y el telescopio, bloquea parte de la luz que emite la estrella. En función de la caída del brillo, es posible determinar si un planeta está rodeando una estrella. Un planeta aparece como un patrón que repite cada órbita a medida que la visión de la Tierra de la estrella se oscurece. Con eso en mente, los investigadores definieron una red neuronal para identificar planetas alrededor de una estrella.
Esta técnica encontró dos planetas diferentes alrededor de dos sistemas estelares separados. Los investigadores planean utilizar el mismo método para explorar las 150.000 estrellas sobre las que el telescopio de Kepler tiene datos. Esto libera a los astrofísicos para investigar otras áreas, ya que no necesitan buscar una aguja en un pajar, mirando manualmente cada imagen para encontrar patrones. Una red neuronal hace el trabajo por ellos. “El aprendizaje automático realmente brilla en situaciones en las que hay tantos datos que los humanos no pueden buscarlos por sí mismos”, declaró Christopher Shallue. *
DESARROLLOS ADICIONALES
Pero estos desarrollos solo raya la superficie. El aprendizaje profundo amplía el horizonte para el potencial de la exploración espacial. Por ejemplo, en la Estación Espacial Internacional, el pequeño robot CIMON de Airbus, Crew Interactive Mobile Companion, habló con el astronauta alemán Alexander Gerst durante 90 minutos el 15 de noviembre de 2018. * Gerst usó un lenguaje muy parecido al utilizado con los asistentes de voz: “Despierta, CIMON”. CIMON es una demostración muy temprana del uso de la IA en el espacio. *
La mayoría de la gente de hoy en día confía en el GPS para localizarse, pero eso no existe en el espacio. Por lo tanto, la NASA e Intel se unieron para resolver los problemas de los viajes espaciales y la colonización utilizando la IA. * Intel organizó un programa de ocho semanas centrado en este esfuerzo. Uno de los nueve equipos desarrolló una herramienta para encontrar la ubicación en el espacio entrenando a una red neuronal para identificar la posición donde se toma una foto. Entrenó a una red neuronal para hacerlo utilizando millones de imágenes reales como datos de entrenamiento.
Por lo tanto, hoy nos concentramos en la Tierra y en las áreas con las que estamos familiarizados, pero el espacio es vasto con posibilidades ilimitadas. Actualmente, existen más de 57 nuevas empresas en la industria espacial, centrándose en áreas como la comunicación y el seguimiento, el diseño y los proveedores de lanzamiento de naves espaciales y la operación de la constelación de satélites. * Esto representa un enorme aumento desde 2012, que vio poca financiación y pocas empresas dedicadas.
IA en el comercio electrónico
- ¿Cómo puede el aprendizaje profundo ayudar al comercio electrónico?
Si duplicas el número de experimentos que haces al año, vas a duplicar tu inventiva.Jeff Bezos
Stitch Fix, un minorista de ropa en línea que comenzó en 2011, ofrece una idea de cómo algunas empresas ya utilizan el aprendizaje automático para crear soluciones más efectivas en el lugar de trabajo. El éxito de la compañía en el comercio electrónico revela cómo la IA y las personas pueden trabajar juntas, con cada lado centrada en sus fortalezas únicas.
Stitch Fix cree que sus algoritmos proporcionan el futuro para el diseño de prendas*, y han utilizado esa tecnología para llevar sus productos al mercado. Los clientes crean una cuenta en el sitio web de Stitch Fix y responden preguntas detalladas sobre cosas como su tamaño, preferencias de estilo y colores preferidos. * La empresa envía un envío de ropa a su casa. Stitch Fix almacena la información de lo que les gusta a los clientes y lo que devuelven.
La diferencia significativa con una empresa de comercio electrónico tradicional es que los clientes no eligen los artículos enviados. Stitch Fix, al igual que un minorista convencional, compra y mantiene su propio inventario para que tengan un amplio stock. Utilizando la información almacenada del cliente, la empresa utiliza un estilista personal para seleccionar cinco artículos para enviar al cliente. El cliente los prueba en la comodidad de su casa, los guarda durante unos días y devuelve cualquier artículo no deseado. Todo el objetivo de la empresa es sobresalir en el estilo personal y enviar a la gente cosas que aman. Parecen estar teniendo éxito, ya que Stitch Fix tiene más de 2 millones de clientes activos y una capitalización de mercado de más de 2 mil millones de dólares.
El problema que tiene Stitch Fix es seleccionar un inventario que coincida con las preferencias de sus clientes. Lo hace en un proceso de dos etapas. El primer paso es recopilar los datos de sus clientes, información sobre su inventario y los comentarios que dejan los clientes. Stitch Fix utiliza este conocimiento para crear un conjunto de recomendaciones, utilizando software de IA, para lo que debe enviar a sus clientes.
El segundo paso implica que los estilistas personales determinen qué artículos recomendados enviar realmente a los clientes. También ofrecen sugerencias de estilo, como cómo personalizar o usar las piezas, antes de empaquetar los artículos y enviarlos a los clientes. Es la combinación creativa de predicción algorítmica y selección humana lo que hace que la oferta de Stitch Fix sea exitosa.
La razón por la que la combinación de humanos y computadoras sobresale en el estilo personal es que los humanos son superiores en el uso de datos no estructurados, que no son fácilmente comprensibles por los ordenadores, y las computadoras funcionan mejor con datos estructurados. Los datos estructurados incluyen detalles como los precios de las casas y las características de las casas, como el número de habitaciones, baños, etc. Los diseños de ropa que son populares en un año determinado son un ejemplo de datos no estructurados.
Sin detenerse ahí, Stitch Fix integró Pinterest en el proceso al permitir a los clientes crear tableros de imágenes que se adapten a su estilo. Stitch Fix transmite esa información al perfil del cliente, y el algoritmo utiliza esa información para coincidir más estrechamente con las piezas de su inventario. En este punto, esta información es más útil para los estilistas humanos, pero no dudo de que los algoritmos sigan aprendiendo.
Otras empresas también utilizan algoritmos de aprendizaje automático para recomendar la ropa o los productos que los usuarios quieren ver. Por ejemplo, Bluecore se centra en ayudar a las empresas de comercio electrónico a recomendar lo que es mejor para los clientes de sus clientes. Si un cliente visita el sitio web de Express, una empresa de ropa, y se registra con un correo electrónico, Bluecore ve que al cliente le gusta una camisa específica y que a los clientes a los que les gusta esa camisa también les gustan un par de pantalones en particular. Bluecore permite a Express enviar correos electrónicos y anuncios personalizados que contengan el mejor conjunto de productos para ese cliente. Los resultados son asombrosos para estas empresas. Los clientes terminan comprando mucho más porque el tipo de ropa que quieren comprar se les ofrece directamente con estos resultados personalizados.
¿Alguna vez te has preguntado cómo Amazon es tan bueno recomendando productos que te atraen o cómo los anuncios de Facebook son (en su mayoría) relevantes? Bueno, utilizan el aprendizaje automático para analizar tus patrones en función de tu historial, así como lo que otros que miraron el mismo artículo que finalmente compraste. Los datos se capturan continuamente para mejorar la experiencia de compra.
La IA y la ley
- ¿Cómo puede ayudar la inteligencia artificial a los abogados?
La justicia no puede ser solo para un lado, pero debe ser para ambos.Eleanor Roosevelt
La ley parece un campo que es poco probable que haga uso de la inteligencia artificial, pero eso está lejos de ser verdad. En este capítulo, quiero mostrar cómo el aprendizaje automático afecta a los campos más improbables. Judicata crea herramientas para ayudar a los abogados a redactar informes legales y tener más probabilidades de ganar sus casos.
Los jueces que presiden los casos judiciales deben pronunciarse de manera justa en las disputas para demandantes y demandados. Sin embargo, un estudio de California mostró que los jueces tienen un sesgo a favor del fiscal, lo que significa que normalmente se pronuncian a favor del demandante. Pero no hay dos personas iguales, y eso es, por supuesto, cierto para los jueces. * Si bien este sesgo es una regla general, no es necesariamente cierto para los jueces individualmente.
Por ejemplo, usemos a los jueces de California Paul Halvonik y Charles Poochigian para mostrar lo diferentes que son los jueces. El juez Halvonik tenía seis veces más probabilidades de decidir a favor de un apelante que el juez Poochigian. Esto podría ser sorprendente, pero es más comprensible dados sus antecedentes.
El juez Halvonik, el primer defensor público estatal de California, fue programado para la Corte Suprema del estado. Desafortunadamente, un cargo por drogas por poseer 300 plantas de marihuana redujo ese sueño y puso fin a su carrera judicial. El juez Poochigian, por otro lado, fue un asambleísta estatal republicano de 1994 a 1998. El gobernador republicano Arnold Schwarzenegger lo nombró miembro de los Tribunales de Apelación de California en 2009.
Si bien no debemos reducir su comportamiento a estereotipos, podemos ver los hechos de cada una de sus resoluciones y cualquier tendencia que pueda desarrollarse a partir de ellos. Para hacer esto, debemos examinar el contexto del tipo de caso y la postura de procedimiento, es decir, cómo se dictaminaron casos similares antes. *
JUDICATA
Judicata, una startup centrada en el uso de la inteligencia artificial para ayudar a los abogados, identifica las estadísticas de cada juez y las utiliza para ver cómo es probable que un juez decida sobre un caso. Tiene en cuenta sus resoluciones basadas en el demandante o el demandado y proporciona una visión de qué otros aspectos podrían cambiar lo que hará el juez, como la causa de la acción o la apelación.
La solicitud de Judicata, Clerk, fue el primer software en leer y analizar los escritos legales, que son documentos legales escritos utilizados en un tribunal para presentar por qué una parte debería ganar contra otra. * El propósito del secretario era aumentar las posibilidades de los abogados de ganar una moción, es decir, ganar una solicitud para que el juez decidiera el caso.
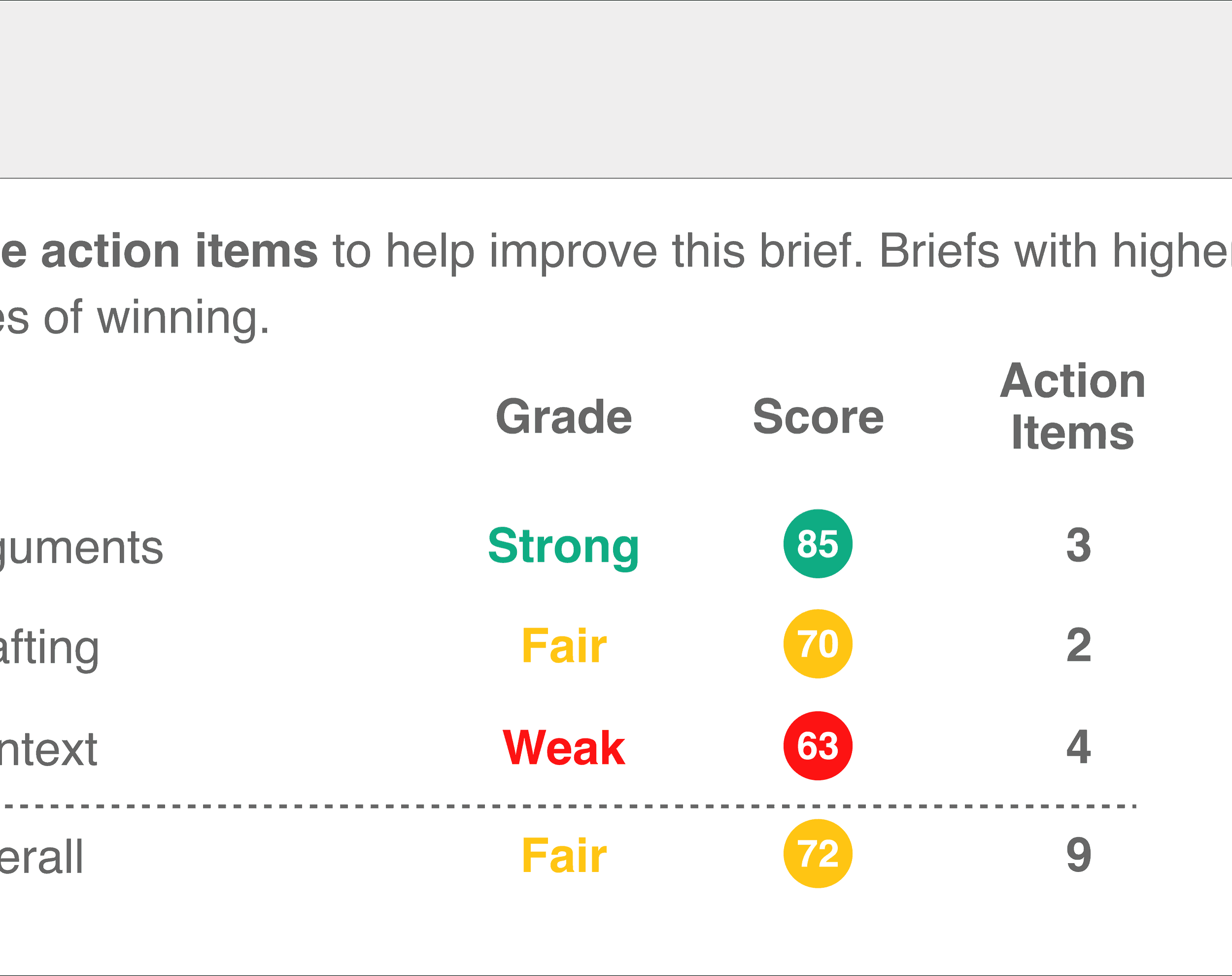
El secretario analiza los informes legales y los evalúa en tres dimensiones: argumentos, redacción y contexto, analízalos de la siguiente manera:
- “Recaradamente en argumentos estratégicos y favorables”.
- “Reforzar esos argumentos con una buena redacción“.
- “Presentar el contexto en el que surge el escrito de una manera favorable”.*
ANALIZAR ARGUMENTOS
La ejecución del abogado en estas tres dimensiones puede juzgarse por una medida objetiva, como:
- “Los escritos ganador funcionan mejor que perder los escritos a lo largo de cada una de estas dimensiones”.
- “Los informes de puntuación más alta tienen más posibilidades de ganar en comparación con los informes de puntuación más baja”.
La capacidad de calificar un informe es crucial porque cualquier cosa que puedas medir, puedes mejorar. Dado un resumen, el programa de Judicata analiza los argumentos dentro del informe legal y los evalúa, en función de si contiene argumentos lógicamente favorables. Analiza todos los casos legales, principios legales y argumentos citados en el documento y determina cuáles son más propensos a ser atacados en base a datos anteriores.
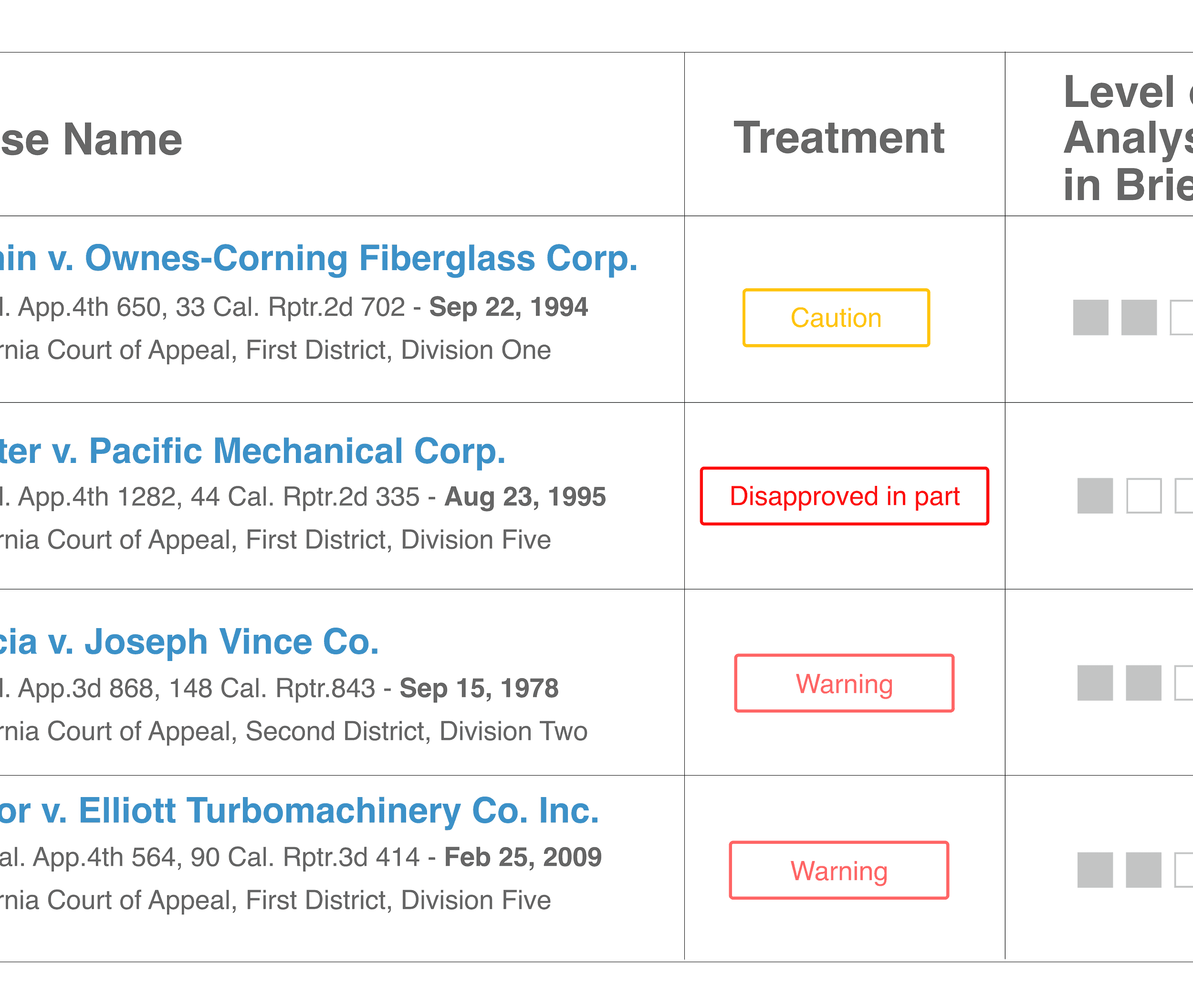
Sobre la base de esa información, crea una instantánea de qué argumentos se utilizaron en qué contextos. Algunos argumentos se utilizan para el demandado y otros para el demandante, la parte que inició la demanda.
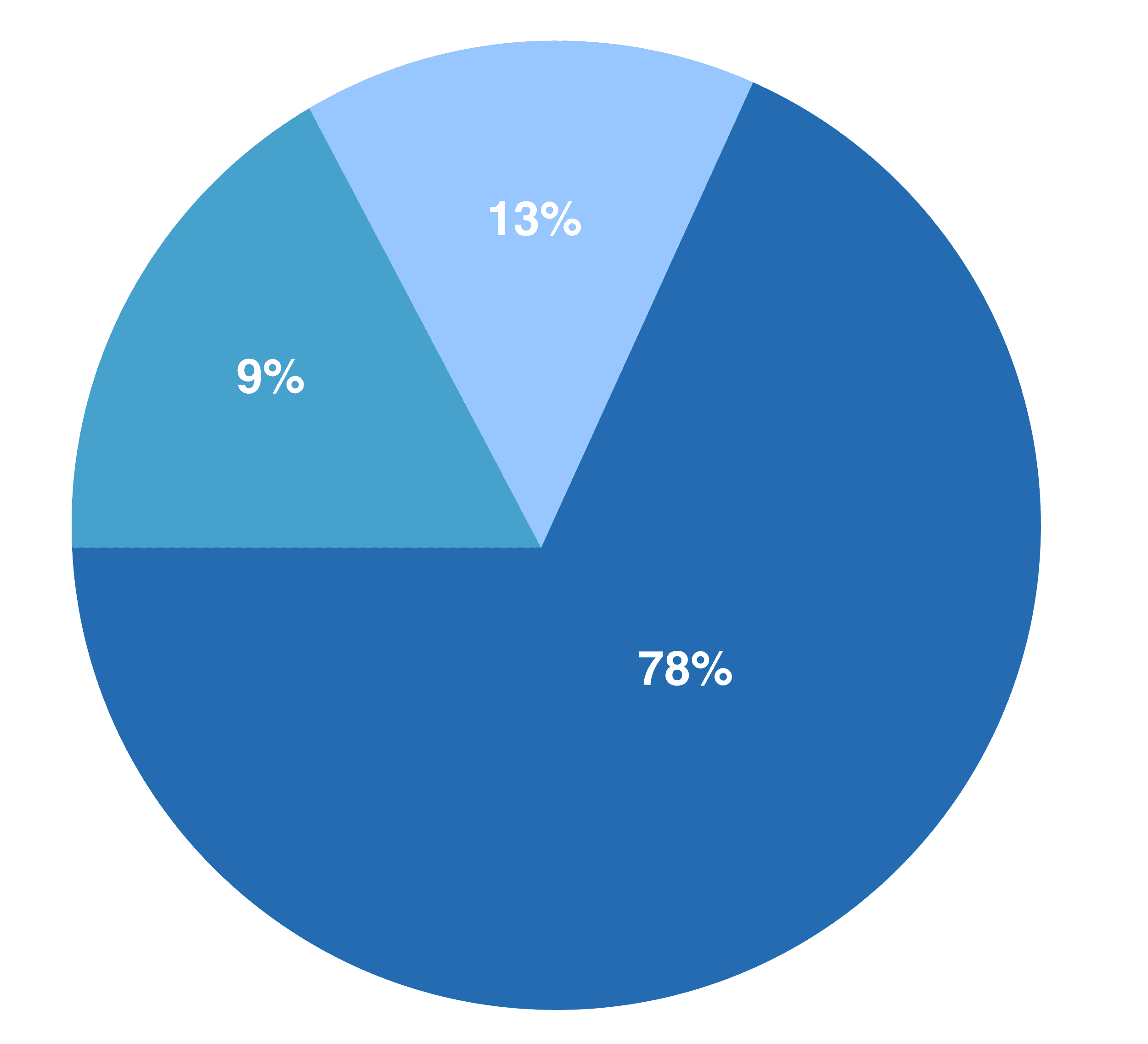
Sorprendentemente, confiar en argumentos que se usaban anteriormente del mismo lado que el abogado funciona mejor. Por lo tanto, si usted es un abogado que defiende un caso, es mejor usar argumentos que se utilizaron por parte del acusado. El secretario también sugiere argumentos que históricamente han funcionado bien para el partido en cuestión. El secretario beneficia a los abogados que quieren crear argumentos favorables y fuertes.

MEJORA DE LOS RESÚMENES
Cada vez que un abogado escribe un informe legal, debe incluir precedentes, casos anteriores que apoyen su caso. Judicata descubrió que los mejores casos para incluir fueron los que coincidían con los mismos resultados deseados que el informe está tratando de lograr. El secretario analiza casos legales anteriores y sugiere precedentes que se utilizaron en casos ganadores, identificando mejores casos para apoyar el informe. El objetivo es ayudar a los abogados a presentar informes mejor redactados.

PREPARANDO CASOS JUSTOS Y EQUILIBRADOS
Los abogados no solo tienen que presentar buenos argumentos y precedentes, sino que también tienen que dirigirse al lado de la oposición. El secretario descubre cuántos argumentos y precedentes deben abordarse en ambos lados y sugiere otros para añadir o eliminar. Con eso, los abogados presentan un caso legal más fuerte, justo y equilibrado.

ANALIZAR EL CONTEXTO DEL CASO
Finalmente, Clerk analiza cuál podría ser el resultado para un determinado juez. Diferentes jueces analizan los casos de manera diferente. Por lo tanto, dependiendo de sus decisiones históricas, Clerk da la probabilidad de que el informe tenga éxito en cada uno de los posibles escenarios.
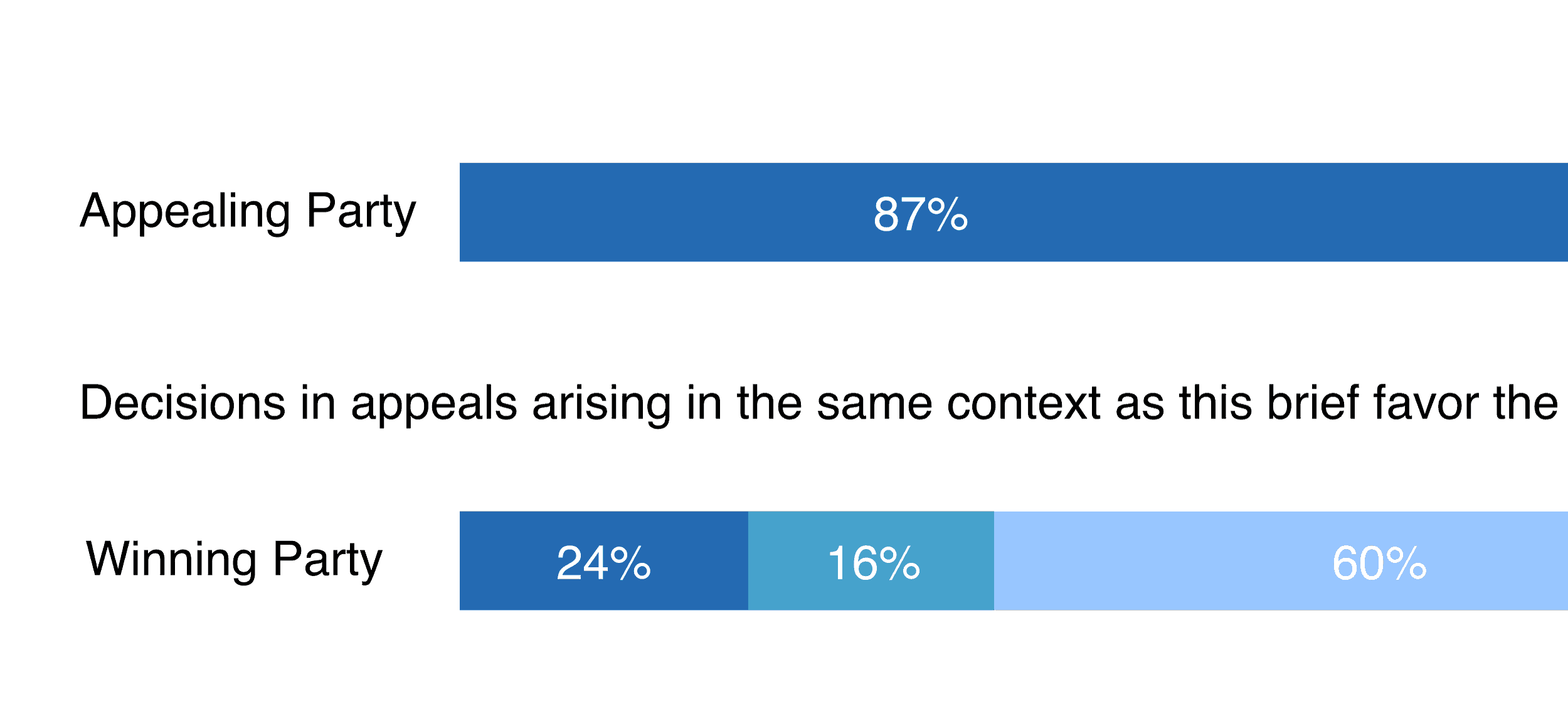
Incluso si el contexto en el que se encuentra un abogado no es favorable, eso no significa que se pierda toda esperanza. El abogado simplemente necesita encontrar casos históricos que inclinen esta tendencia a su favor. E incluso si el abogado no tiene más del 50 % de posibilidades de ganar el caso, el fallo aún puede ir a su favor. Con Clerk, los abogados pueden discutir mejor su caso. La justicia se dice que es ciega, pero cuando no lo es, el aprendizaje automático puede ayudar a los abogados a presentar su caso.
IA y bienes raíces
- ¿Cómo predice Opendoor los precios de la vivienda?
- ¿Qué hay detrás de los algoritmos de Opendoor?
- ¿Cómo utiliza Opendoor el aprendizaje automático?
Me sorprende cómo la gente a menudo está más dispuesta a actuar sobre la base de pocos o ningún dato que a usar datos que son un desafío para reunir.Robert Shiller*
Las casas son la posesión más cara que tiene el estadounidense promedio, pero también son las más difíciles de intercambiar. * Es difícil vender una casa a toda prisa cuando alguien necesita el dinero en efectivo, pero el aprendizaje automático podría ayudar a resolverlo. Keith Rabois, un veterano tecnológico que trabajó en puestos ejecutivos en PayPal, LinkedIn y Square, fundó Opendoor para resolver este problema. Su premisa es que cientos de miles de estadounidenses valoran la certeza de una venta en lugar de obtener el precio más alto. Opendoor cobra una tarifa más alta que un agente inmobiliario tradicional, pero a cambio, ofrece ofertas para casas extremadamente rápido. El lema de Opendoor es: “Obtén una oferta en tu casa con solo pulsar un botón”.
Opendoor compra una casa, soluciona los problemas recomendados por los inspectores e intenta venderla por un pequeño beneficio. * Para tener éxito, Opendoor debe fijar el precio preciso y rápido de las casas que compra. Si los precios de Opendoor de la casa son demasiado bajos, los vendedores no tienen ningún incentivo para vender su casa a través de la plataforma. Si el precio de la casa es demasiado alto, entonces podría perder dinero al vender la casa. Opendoor necesita encontrar el precio justo de mercado para cada casa.
Los bienes raíces son la clase de activos más grande de los Estados Unidos, representando 25 billones de dólares, por lo que el potencial de Opendoor es enorme. Pero para que Opendoor haga la oferta adecuada, debe usar toda la información que tiene sobre una casa para determinar el precio apropiado. Opendoor se centra en el medio del mercado y no hace ofertas en casas en mal estado o de lujo porque sus precios no son predecibles.
Opendoor construye programas que predicen el precio de una casa. * Lo hace analizando las características en las que un comprador en el mercado pensaría y luego enseñando a sus modelos a mirar esas características. Opendoor analiza tres factores principales:
- las cualidades del hogar,
- el barrio de la casa, y
- los precios de las casas vecinas a lo largo del tiempo.
Si le dijera a alguien que está vendiendo una casa de 2.000 pies cuadrados en Phoenix con dos baños y cuatro dormitorios, ¿puede el comprador dar un precio? No, no pueden. El comprador tiene que ver la casa. Del mismo modo, el modelo Opendoor necesita determinar el precio de una casa a partir de datos duros que han convertido en algo que sea legible por máquina y que los algoritmos puedan analizar. Por lo tanto, Opendoor también toma fotos de la casa para que pueda analizar más que el número de dormitorios y otras características. Las imágenes muestran más datos cualitativos y cuantitativos en comparación con el número de habitaciones.
Las imágenes informan a Opendoor sobre información cuantitativa, como si hay una piscina en el patio trasero, el tipo de suelo y el estilo de los gabinetes. Pero otras características también son importantes para fijar el precio de una casa, y son mucho más difíciles de identificar. Por ejemplo, ¿la apariencia de la casa es buena, y tiene atractivo en la acera? Las imágenes rellenan los detalles de los hechos brutos. Si bien estas características están presentes en las imágenes, no todas son fácilmente identificables por algoritmos. Opendoor identifica estas características utilizando tanto el aprendizaje profundo para extraer parte de la información en información legible por máquina, como crowdsourcing, es decir, utilizando un gran número de personas, para hacer parte del trabajo. Opendoor necesita crowdsourcing para las cualidades que son menos cuantificables con el fin de convertir estas señales visuales en datos estructurados.
Después de eso, Opendoor toma los datos y los analiza, añadiendo otros factores, como en qué barrio se encuentra la casa y su ubicación en esa área. Pero eso tampoco es fácil porque incluso si las casas están cerca unas de otras, sus precios varían dependiendo de muchos otros factores. Por ejemplo, si una casa está demasiado cerca de una autopista grande y ruidosa, entonces el precio de la casa podría ser más bajo que el de una casa en el mismo vecindario, pero más lejos de la autopista. Estar ubicado junto a un campo de fútbol o un centro comercial puede afectar al precio. Muchas cosas afectan al precio de una vivienda.
La siguiente etapa es determinar el precio de una casa a lo largo del tiempo. La misma casa tiene un precio diferente dependiendo de cuándo se venda. Por lo tanto, Opendoor necesita identificar cómo cambian los precios con el tiempo. Por ejemplo, antes de la burbuja de 2008, los precios de las viviendas eran extremadamente altos, pero se desplomaron después de la explosión de la burbuja. Opendoor debe averiguar cuál debe ser el precio de una casa, dependiendo del mercado en el momento en que se vende.
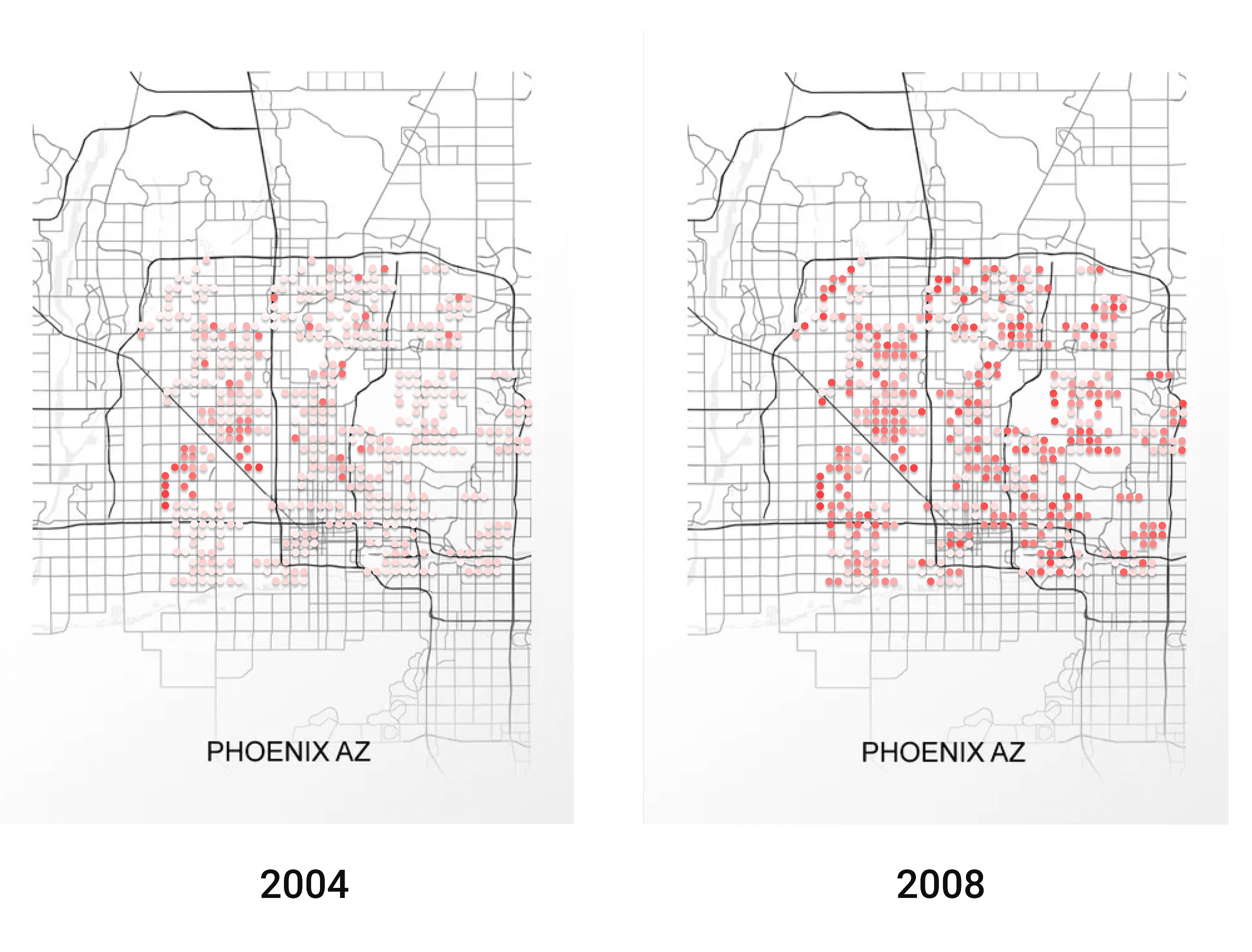
La primera imagen aquí muestra el precio de las casas en un mercado normal. La segunda imagen presenta los precios de las casas en Phoenix justo antes de que explotara la burbuja de la vivienda. Y, la tercera imagen muestra los precios de las casas justo después de que explotara la burbuja de la vivienda.
Opendoor no solo necesita pensar en el precio, sino también en la liquidez del mercado: cuánto tiempo tarda en promedio una casa en venderse en un determinado mercado. ¿Qué tan dispuesto está el mercado a aceptar una casa que Opendoor está a punto de comprar y revender? Opendoor tiene que fijar el precio del riesgo que asume al hacer una oferta. La liquidez afecta a la cantidad de casas que la empresa puede comprar en un período determinado y a la cantidad de riesgo que está asumiendo. Cuanto más tarde una casa en venderse, mayor será el riesgo. Cuanto más puede variar el precio, peor será para Opendoor porque quiere pagar un precio justo por cada casa.
Otros competidores se están poniendo al día y ofreciendo servicios similares, lo que beneficia a los clientes. Por ejemplo, en 2018, Zillow comenzó a ofrecer un servicio para comprar casas con una “oferta en efectivo”, requiriendo que el cliente solo ingresara información sobre la casa, incluidas las fotos. * Zillow predice el precio de estas casas con la ayuda del aprendizaje automático. *
La inteligencia artificial también se está utilizando para predecir a los clientes que es probable que no superen una verificación de crédito o que impagon su hipoteca. Esto va de la mano con los sistemas de gestión de relaciones con los clientes (CRM) mediante el seguimiento de cuándo es probable que los clientes quieran mudarse. Esta misma tecnología se aplica a la administración de propiedades para predecir tendencias como los precios de la propiedad, los requisitos de mantenimiento y las estadísticas de delincuencia. *
Y finalmente, al igual que con la IA que afecta a los mercados laborales de los conductores de camiones y taxis, la tecnología podría significar menos puestos de trabajo para los agentes inmobiliarios. * Sin embargo, predigo la colaboración entre la IA y los humanos como con Stitch Fix. Hay un componente personal y subjetivo en los bienes raíces, por lo que este campo es la oportunidad perfecta para elevar el mercado y proporcionar una mejor experiencia para los compradores y vendedores de viviendas con IA.