



Indice de Contenido
- Los principales enfoques del aprendizaje automático
- Redes neuronales profundas
- Redes neuronales convolucionales
- Google Brain: La primera red neuronal a gran escala
- DeepMind: Aprender de la experiencia
- AlphaGo: Derrotando a los mejores jugadores de Go
- OpenAI
- Software 2.0
- Duelo de redes neuronales
- Los datos son el nuevo petróleo
- Privacidad de datos
- Procesadores de aprendizaje profundo
El cambio fundamental en la resolución de problemas que el razonamiento probabilístico trajo a la IA de 1993 a 2011 fue un gran paso adelante, pero la probabilidad y las estadísticas solo llevaron a los desarrolladores hasta ahora. Geoffrey Hinton creó una técnica innovadora llamada retropropagación para marcar el comienzo de la próxima era de la inteligencia artificial: el aprendizaje profundo. Su trabajo con redes neuronales multicapa es la base del desarrollo moderno de la IA.
El aprendizaje profundo es una clase de métodos de aprendizaje automático que utiliza redes neuronales multicapa que se entrenan a través de técnicas como el aprendizaje supervisado, no supervisado y de refuerzo.
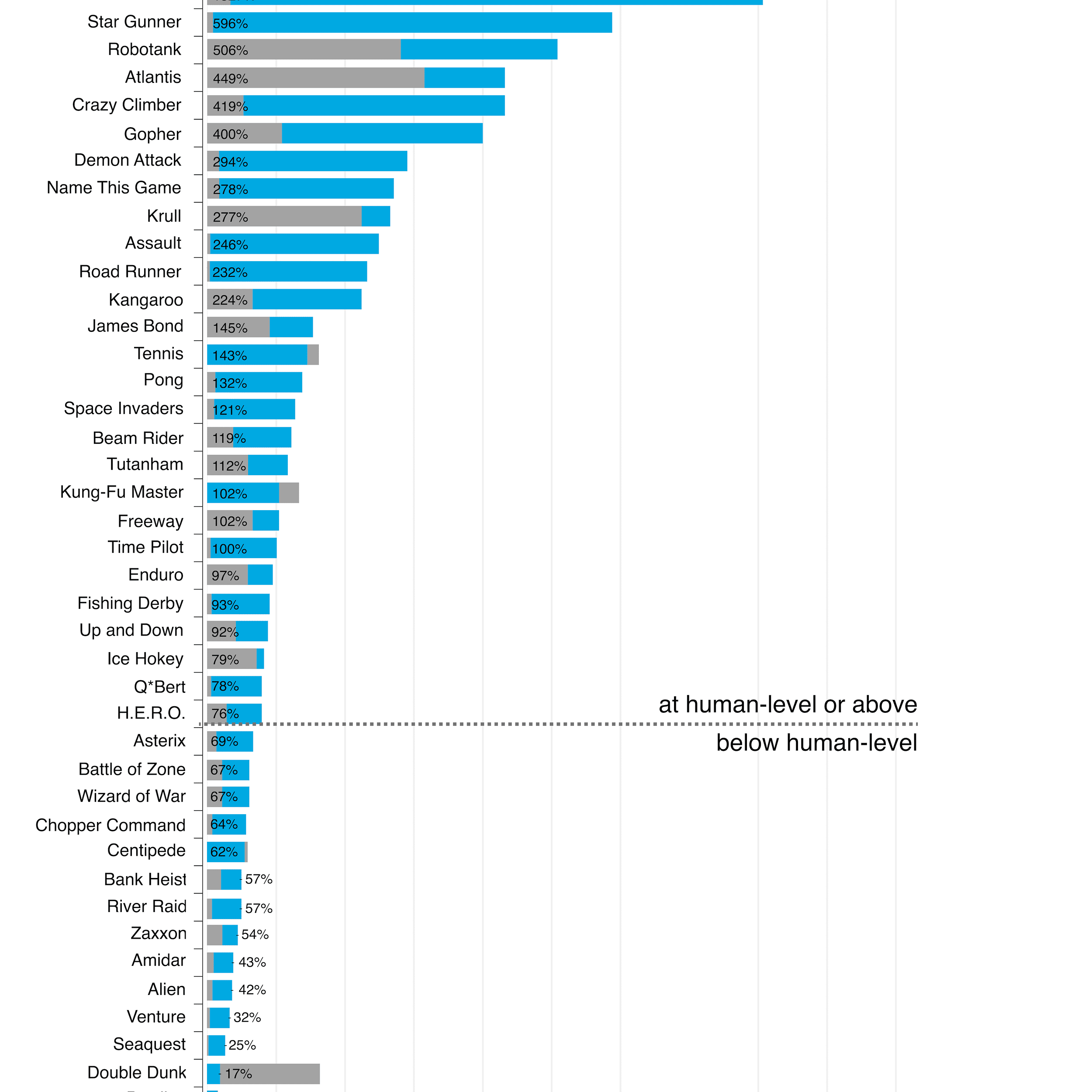
En 2012, Geoffrey Hinton y los estudiantes de su laboratorio demostraron que las redes neuronales profundas, entrenadas con retropropagación, superan a los mejores algoritmos en reconocimiento de imágenes por un amplio margen.
Justo después de eso, el aprendizaje profundo despegó desbloqueando un montón de potencial. Su primer uso a gran escala fue con Google Brain. Dirigido por Andrew Ng, que alimentó 10 millones de vídeos de YouTube a 1.000 ordenadores, el sistema fue capaz de reconocer gatos y detectar caras sin reglas codificadas.
Luego, DeepMind utilizó el aprendizaje profundo para crear el primer sistema de aprendizaje automático para derrotar a los mejores jugadores de Go del mundo. DeepMind combinó técnicas de jugadores anteriores de Go, utilizando la búsqueda en el árbol de Monte Carlo combinada con dos redes neuronales profundas que calcularon la probabilidad de los próximos movimientos posibles y las posibilidades de ganar de cada uno de ellos. Este fue un gran avance debido a lo difícil que es el juego en comparación con otros juegos como el ajedrez. El número total de estados es mayor en comparación con el ajedrez.
El mismo equipo utilizó redes neuronales profundas para determinar la estructura 3D de las proteínas en función de su genoma, creando lo que se conoce como AlphaFold. Esta fue una solución para un gran desafío de 50 años en biología. *
Surgieron nuevas técnicas, incluida la creación de redes adversarias generativas, que tienen dos redes neuronales jugando un juego de gato y ratón en el que una crea imágenes falsas que se parecen a las reales alimentadas y la otra decide si son reales. Esta nueva técnica se ha utilizado para crear imágenes que parecen reales.
Si bien el aprendizaje profundo requirió la creación de un nuevo sistema de software, TensorFlow, y un nuevo hardware, unidades de procesamiento gráfico (GPU) y unidades de procesamiento de tensores (TPU), lo que más se necesitaba era una forma de entrenar estas redes de neuroales profundos. El aprendizaje profundo solo tiene tanto éxito como los datos de entrenamiento. El trabajo de Fei-Fei Li creó un conjunto de datos instrumental, ImageNet, que se utilizó no solo para entrenar los algoritmos, sino también como punto de referencia en el campo. Sin esos datos, el aprendizaje profundo no estaría donde está hoy.
Desafortunadamente, con la recopilación de datos a una escala tan masiva, los problemas de privacidad se convierten en una preocupación. Si bien hemos llegado a esperar violaciones de datos, no tiene por qué ser así. Apple y Google continúan afinando los enfoques que no requieren la recopilación de datos personales. La privacidad diferencial y el aprendizaje federado son ejemplos de la tecnología actual. Permiten a los modelos actualizarse y aprender sin filtrar información individual sobre los datos que se utilizan para el entrenamiento.
Los principales enfoques del aprendizaje automático
Aprendí muy pronto la diferencia entre saber el nombre de algo y saber algo.Richard Feynman*
Los algoritmos de aprendizaje automático generalmente aprenden analizando datos e infiriendo qué tipo de modelo o parámetros debería tener un modelo o interactuando con el entorno y obteniendo retroalimentación de él. Los humanos pueden anotar estos datos o no, y el entorno puede ser simulado o el mundo real.
Las tres categorías principales que los algoritmos de aprendizaje automático pueden utilizar para aprender son el aprendizaje supervisado, el aprendizaje no supervisado y el aprendizaje por refuerzo. Se pueden utilizar otras técnicas, como estrategias de evolución o aprendizaje semisupervisado, pero no son tan ampliamente utilizadas ni tan exitosas como las tres técnicas anteriores.
APRENDIZAJE SUPERVISADO
El aprendizaje supervisado se ha utilizado ampliamente en la formación de ordenadores para etiquetar objetos en imágenes y traducir la voz a texto. Digamos que eres dueño de un negocio de bienes raíces y uno de los aspectos más importantes del éxito es averiguar el precio de una casa cuando entra en el mercado. Determinar ese precio es extremadamente importante para completar una venta, lo que hace feliz tanto al comprador como al vendedor. Usted, como agente inmobiliario experimentado, puede calcular el precio de una casa en función de sus conocimientos previos.
Pero a medida que tu negocio crece, necesitas ayuda, por lo que contratas a nuevos agentes inmobiliarios. Para tener éxito, también necesitan determinar el precio de una casa en el mercado. En aras de ayudar a estas personas inexpertas, escribe el valor de las casas que la empresa ya compró y vendió, en función del tamaño, el vecindario y varios detalles, incluido el número de baños y dormitorios y el precio de venta final.
| DORMITORIOS | PIES CUADRADOS | VECINDARIO | PRECIO DE VENTA |
|---|---|---|---|
| 2 | 1.000 | Colina Potrero | 300 000 $ |
| 1 | 700 | Parche para perros | 250 000 $ |
| 2 | 1.250 | haoma | 500 000 $ |
| 1 | 800 | Colina Potrero | 200 000 $ |
| 1 | 400 | haoma | 150 000 $ |
Tabla: Datos de muestra para un algoritmo de aprendizaje supervisado.
Esta información se llama datos de entrenamiento; es decir, son datos de ejemplo que contienen los factores o características que pueden influir en el precio de una casa además del precio de venta final. Los nuevos empleados analizan todos estos datos para empezar a aprender qué factores influyen en el precio final de una casa. Por ejemplo, el número de habitaciones podría ser un gran indicador de precio, pero el tamaño de la casa puede no ser necesariamente tan importante. Si los agentes inmobiliarios inexpertos tienen que determinar el precio de una casa nueva que entra en el mercado, simplemente comprueban para encontrar una casa que sea más similar y usan esa información para determinar el precio.
| DORMITORIOS | PIES CUADRADOS | VECINDARIO | PRECIO DE VENTA |
|---|---|---|---|
| 2 | 1.000 | Parche para perros | ??? |
Tabla: Falta información que el algoritmo determinará.
Así es precisamente como los algoritmos aprenden de los datos de entrenamiento con un método llamado aprendizaje supervisado. El algoritmo conoce el precio de algunas de las casas en el mercado, y necesita averiguar cómo predecir el nuevo precio de una casa que está entrando en el mercado. En el aprendizaje supervisado, la computadora, en lugar de los agentes inmobiliarios, calcula la relación entre los puntos de datos. El valor que el ordenador necesita predecir se llama etiqueta. En los datos de entrenamiento, se proporcionan las etiquetas. Cuando hay un nuevo punto de datos cuyo valor, la etiqueta, no está definido, el ordenador estima el valor que falta comparándolo con los que ya ha visto.
APRENDIZAJE NO SUPERVISADO
El aprendizaje no supervisado es una técnica de aprendizaje automático que aprende patrones con datos sin etiquetar.
En nuestro ejemplo, el aprendizaje no supervisado es similar al aprendizaje supervisado, pero el precio de cada casa no forma parte de la información incluida en los datos de entrenamiento. Los datos no están etiquetados.
| DORMITORIOS | PIES CUADRADOS | VECINDARIO |
|---|---|---|
| 3 | 2.000 | Parche para perros |
| 2 | 800 | Colina Potrero |
| 3 | 1.000 | haoma |
| 1 | 600 | Parche para perros |
| 4 | 2.000 | Colina Potrero |
Tabla: Datos de entrenamiento de muestra para un algoritmo de aprendizaje no supervisado.
Incluso sin el precio de las casas, puedes descubrir patrones a partir de los datos. Por ejemplo, los datos pueden decir que hay una gran cantidad de casas con dos dormitorios y que el tamaño promedio de una casa en el mercado es de alrededor de 1.200 pies cuadrados. Otra información que se podría extraer es que muy pocas casas en el mercado en un determinado vecindario tienen cuatro dormitorios, o que existen cinco estilos principales de casas. Y con esa información, si una casa nueva entra en el mercado, puede averiguar las casas más similares mirando las características o identificando que la casa es un valor atípico. Esto es lo que hacen los algoritmos de aprendizaje no supervisados.
APRENDIZAJE DE REFUERZO
Las dos formas de aprendizaje anteriores se basan únicamente en los datos dados al algoritmo. El proceso de aprendizaje por refuerzo es diferente: el algoritmo aprende interactuando con el entorno. Recibe comentarios del medio ambiente, ya sea recompensando el buen comportamiento o castigando lo malo. Veamos un ejemplo de aprendizaje por refuerzo.
Digamos que tienes un perro, Spot, a quien quieres entrenar para sentarse al mando. ¿Por dónde empiezas? Una forma es mostrarle a Spot lo que significa “sentado” poniendo su trasero en el suelo. La otra forma es recompensar a Spot con un regalo cada vez que pone su trasero en el suelo. Con el tiempo, Spot se entera de que cada vez que se sienta al mando recibe un regalo y que este es un comportamiento recompensado.
El aprendizaje de refuerzo funciona de la misma manera. Es un marco construido sobre esta visión que puedes enseñar a los agentes inteligentes, como un perro o una red de neuroales profundos, a lograr una determinada tarea recompensándolos cuando realizan correctamente la tarea. Y cada vez que el agente logra el resultado deseado, su posibilidad de repetir dicha acción aumenta debido a la recompensa. Los agentes son algoritmos que procesan la entrada y actúan como una voz para la salida. Spot es el agente en el ejemplo.
El aprendizaje de refuerzo es un método de entrenamiento de aprendizaje automático basado en recompensar los comportamientos deseados y/o castigar a los no deseados.
El aprendizaje de refuerzo como marco de aprendizaje es interesante, pero los algoritmos asociados son el aspecto más importante. La forma en que trabajan es definiendo la recompensa que el agente recibe una vez que alcanza un estado, como sentarse. La formulación de algoritmos de refuerzo es encontrar una política, como un mapeo específico de los estados a las acciones a tomar, que maximice la recompensa esperada para que el agente aprenda el comportamiento que maximiza la recompensa (el tratamiento).
En la formulación de aprendizaje de refuerzo, el entorno da la recompensa: el agente no descubre la recompensa en sí, sino que solo la recibe interactuando con el entorno y golpeando el comportamiento esperado. Un problema con esto es que el agente a veces tarda mucho tiempo en recibir una recompensa. Por ejemplo, si Spot nunca se sienta, entonces nunca recibe un regalo y no aprende a sentarse. O, digamos que quieres que un agente aprenda a navegar por un laberinto y la recompensa solo se da cuando el agente sale del laberinto. Si el agente tarda demasiado en irse, entonces es difícil decir qué acciones tomó el agente que le ayudaron a salir del laberinto. Otro problema es que el agente solo aprende de sus propios éxitos y fracasos. Ese no es necesariamente el caso de los humanos en el mundo real. Nadie necesita conducir por un acantilado miles de veces para aprender a conducir. La gente puede obtener recompensas a partir de la observación.
ALGORITMOS DE REFUERZO
Los siguientes dos pasos definen los algoritmos de refuerzo:
- Añade aleatoriedad a las acciones del agente para que intente algo diferente, y
- Si el resultado fue mejor de lo esperado, haz más de lo mismo en el futuro.
Añadir aleatoriedad a las acciones garantiza que el agente busque las acciones correctas a realizar. Y si el resultado es el esperado, entonces el agente intenta hacer más de lo mismo en el futuro. Sin embargo, el agente no necesariamente repite exactamente las mismas acciones, porque todavía intenta mejorar explorando acciones potencialmente mejores. Aunque los algoritmos de refuerzo se pueden explicar fácilmente, no necesariamente funcionan para todos los problemas. Para reforzar el aprendizaje de trabajar, la situación debe tener una recompensa, y no siempre es fácil definir lo que debe o no debe ser recompensado.
Los algoritmos de refuerzo también pueden ser contraproducente. Digamos que un agente es recompensado por el número de clips que hace. Si el agente aprende a transformar algo en clips, podría ser que lo convierta todo en clips. * Si la recompensa no castiga al agente cuando crea demasiados clips de papel, el agente puede comportarse mal. Los algoritmos de aprendizaje de refuerzo también son en su mayoría ineficientes porque pasan mucho tiempo buscando la solución correcta y añadiendo acciones aleatorias para encontrar el comportamiento correcto. Incluso con estas limitaciones, pueden realizar una abrumadora variedad de tareas, como jugar a juegos de Go a nivel sobrehumano y hacer que los brazos robóticos agarren objetos.
Otra forma de aprender que es particularmente útil con los juegos es hacer que varios agentes jueguen entre sí. Dos ejemplos clásicos son el ajedrez o el Go, donde dos agentes compiten entre sí. Los agentes aprenden qué acciones tomar al ser recompensados cuando ganan el juego. Esta técnica se llama juego personal, y se puede utilizar no solo con un algoritmo de aprendizaje de refuerzo, sino también para generar datos. En Go, por ejemplo, se puede usar para averiguar qué jugadas tienen más probabilidades de hacer ganar a un jugador. Self-play genera datos a partir de la potencia informática, es decir, del ordenador que se reproduce a sí mismo.
Las tres categorías de aprendizaje son útiles en diferentes situaciones. Utilice el aprendizaje supervisado cuando hay muchos datos disponibles que las personas etiquetan, como cuando otros etiquetan a las personas en Facebook.El aprendizaje no supervisado se utiliza principalmente cuando no hay mucha información sobre los puntos de datos que el sistema necesita averiguar, como en los ataques cibernéticos. Se puede inferir que están siendo atacados mirando los datos y viendo comportamientos extraños que no estaban allí antes del ataque. El último, el aprendizaje de refuerzo, se utiliza principalmente cuando no hay muchos datos sobre la tarea que el agente necesita lograr, pero hay objetivos claros, como ganar un juego de ajedrez. Los algoritmos de aprendizaje automático, más específicamente los algoritmos de aprendizaje profundo, se entrenan con estos tres modos de aprendizaje.
Redes neuronales profundas
- ¿Qué es una red neuronal?
- ¿Qué es la retropropagación?
- ¿Qué son las redes neuronales convolucionales?
Siempre he estado convencido de que la única manera de hacer que la inteligencia artificial funcione es hacer el cálculo de una manera similar al cerebro humano. Ese es el objetivo que he estado persiguiendo. Estamos progresando, aunque todavía tenemos mucho que aprender sobre cómo funciona realmente el cerebro.Geoffrey Hinton*
EL AVANCE
El aprendizaje profundo es un tipo de algoritmo de aprendizaje automático que utiliza redes neuronales multicapa y retropropagación como técnica para entrenar las redes neuronales. El campo fue creado por Geoffrey Hinton, el tatarabuelo de George Boole, cuyo álgebra booleana es una piedra angular de la computación digital. *
La evolución del aprendizaje profundo fue un proceso largo, por lo que debemos retroceder en el tiempo para entenderlo. La técnica surgió por primera vez en el campo de la teoría del control en la década de 1950. Una de las primeras aplicaciones consistió en optimizar los empujes de las naves espaciales Apolo mientras se dirigían a la luna.
Las primeras redes neuronales, llamadas perceptrones, fueron el primer paso hacia la inteligencia humana. Sin embargo, un libro de 1969, Perceptrons: An Introduction to Computational Geometry de Marvin Minsky y Seymour Papert, demostró las limitaciones extremas de la tecnología al mostrar que una red superficial, con solo unas pocas capas, solo podía realizar las funciones computacionales más básicas. En ese momento, su libro fue un gran revés en el campo de las redes neuronales y la IA.
Para superar las limitaciones señaladas en el libro de Minsky y Papert requiere redes neuronales de múltiples capas. Para crear una red neuronal multicapa para realizar una determinada tarea, los investigadores primero determinan cómo se verá la red neuronal determinando qué neuronas se conectan a qué otras. Pero para terminar de crear una red neuronal de este tipo, los investigadores necesitan encontrar los pesos entre cada una de las neuronas, cuánto afecta la producción de una neurona a la siguiente. El paso de entrenamiento en el aprendizaje profundo suele hacer eso. En ese paso, la red neuronal se presenta con ejemplos de datos y el software de entrenamiento calcula los pesos correctos para cada conexión en la red neuronal para que produzca los resultados previstos; por ejemplo, si la red neuronal está entrenada para clasificar imágenes, entonces cuando se presenta con imágenes que contienen gatos, dice que hay un gato allí.
La retropropagación es un algoritmo que ajusta los pesos de tal manera que cada vez que los cambias, la red neuronal se acerca a la salida correcta más rápido de lo que era posible anteriormente. La forma en que esto funciona es que las neuronas que están más cerca de la salida son las que se ajustan primero. Luego, después de que toda la clasificación de las imágenes no se pueda mejorar ajustando, la capa anterior se actualiza para mejorar la clasificación. Este proceso continúa hasta que la primera capa de neuronas es la que se ajusta.
En 1986, Hinton publicó el artículo seminal sobre redes neuronales profundas (DNN), “Aprender representaciones mediante errores de retropropagación”, con sus colegas David Rumelhart y Ronald Williams. * El artículo introdujo la idea de retropropagación, una técnica matemática simple que condujo a grandes avances en el aprendizaje profundo.
La técnica de retropropagación desarrollada por Hinton encuentra los pesos de cada neurona en una red neuronal multicapa de manera más eficiente. Antes de esta técnica, se tardó una cantidad exponencial de tiempo en encontrar los pesos, también conocidos como coeficientes, para una red neuronal multicapa, lo que hizo extremadamente difícil encontrar los coeficientes correctos para cada neurona. Antes, tardó meses o años en entrenar una red neuronal para ser la correcta para las entradas, pero esta nueva técnica tomó significativamente menos tiempo.
El avance de Hilton también mostró que la retropropagación permitió entrenar fácilmente una red neuronal que tenía más de dos o tres capas, rompiendo la limitación impuesta por las redes neuronales poco profundas. La retropropagación permitió la innovación de encontrar los pesos exactos para que una red neuronal multicapa creara la salida o el resultado deseado. Este desarrollo permitió a los científicos entrenar redes neuronales más potentes, haciéndolas mucho más relevantes. En comparación, una de las redes neuronales de mayor rendimiento en la visión, llamada Inception, tiene aproximadamente 22 capas de neuronas.
¿QUÉ ES UNA RED NEURONAL?
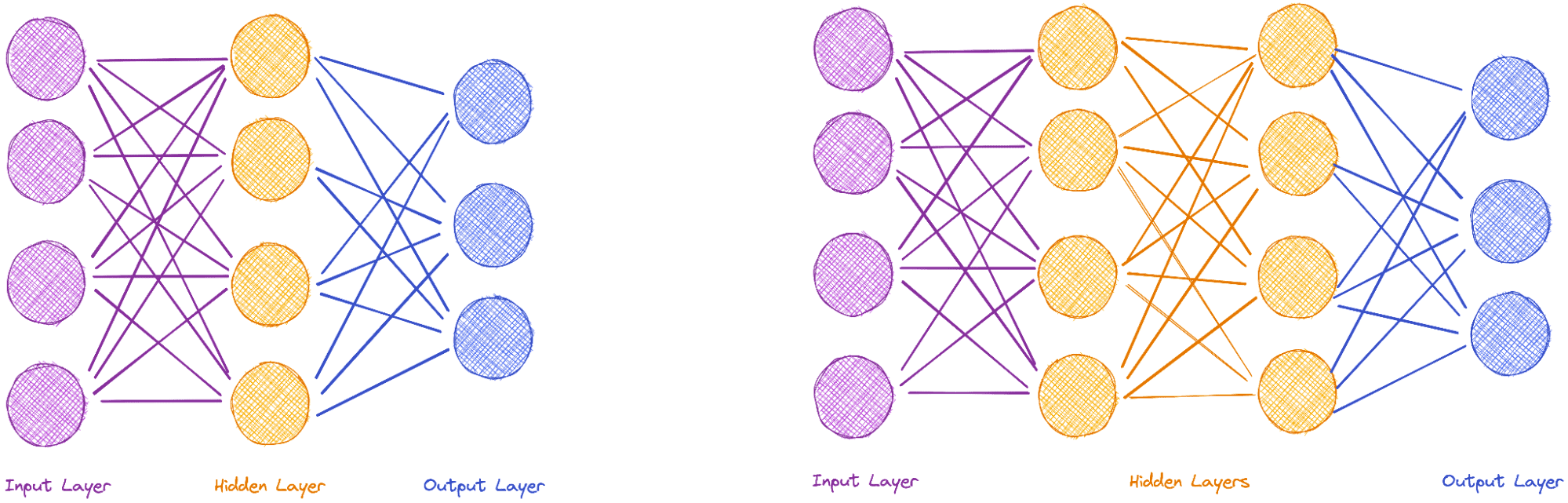
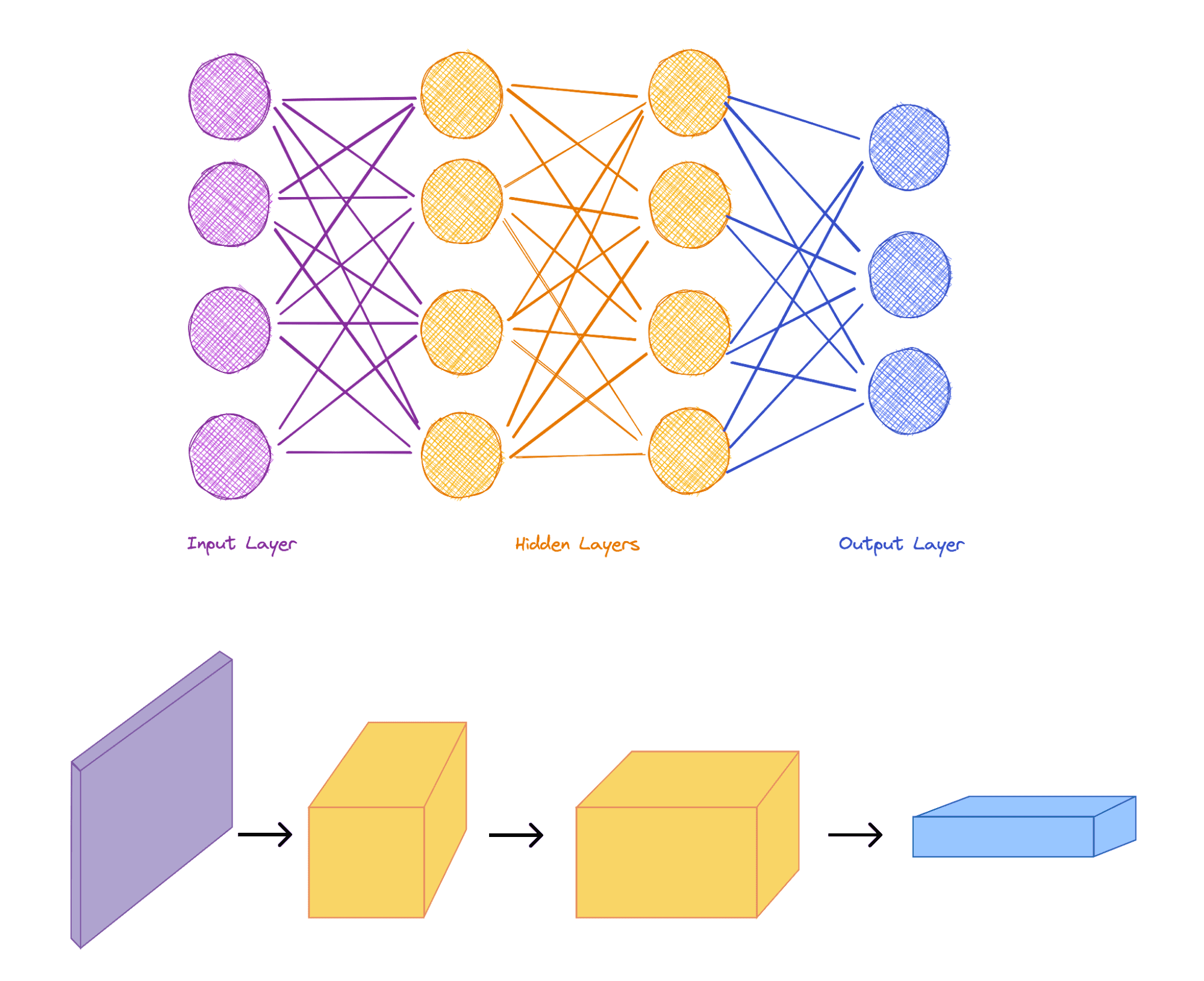
La siguiente figura muestra un ejemplo tanto de una red neuronal simple (SNN) como de una red neuronal de aprendizaje profundo (DLNN). A la izquierda de cada red se encuentra la capa de entrada, representada por los puntos rojos. Estos reciben los datos de entrada. En el SNN, las neuronas de capa oculta se utilizan para hacer los ajustes necesarios para alcanzar la salida (puntulos azules) en el lado derecho. Por el contrario, el uso de más de una capa caracteriza el DLNN, lo que permite un comportamiento mucho más complejo que puede manejar una entrada más involucrada.
La forma en que los investigadores suelen desarrollar una red neuronal es la primera vez definiendo su arquitectura: el número de neuronas y cómo están dispuestas. Pero los parámetros de las neuronas dentro de la red neuronal deben determinar. Para ello, los investigadores inicializan los pesos de la red neuronal con números aleatorios. Después de eso, le dan los datos de entrada y determinan si la salida es similar a la que quieren. Si no lo es, entonces actualizan los pesos de las neuronas hasta que la salida sea la más cercana a lo que muestran los datos de entrenamiento.
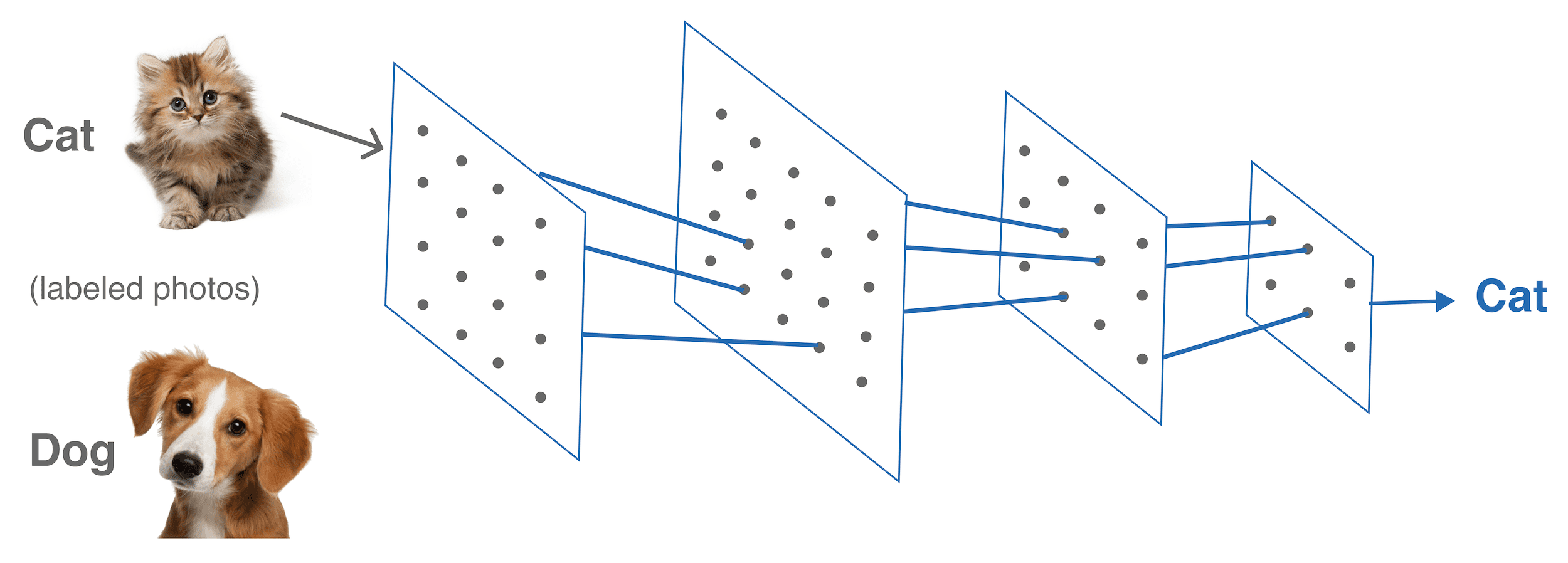
Por ejemplo, digamos que quieres clasificar algunas imágenes como que contienen un perrito caliente y otras como que no contienen un perro caliente. Para ello, alimentas las imágenes de la red neuronal que contienen perritos calientes y otras que no lo hacen, que son los datos de entrenamiento. Después del entrenamiento inicial, la red neuronal recibe nuevas imágenes y necesita determinar si contienen un perrito caliente o no.
Estas imágenes de entrada están compuestas por una matriz de números, que representa cada píxel. La red neuronal pasa a través de la imagen, y cada neurona aplica la multiplicación de matrices, utilizando los pesos internos, a los números de la imagen, generando una nueva imagen. Las salidas de las neuronas son una pila de imágenes de menor resolución, que luego se multiplican por las neuronas de la siguiente capa. En la capa final, sale un número que representa la solución. En este caso, si es positivo, significa que la imagen contiene un perrito caliente, y si es negativo, significa que no contiene un perrito caliente.
El problema es que los pesos no se definen al principio. El proceso de encontrar los pesos, conocido como entrenamiento de la red, que producen un número positivo para las imágenes que contienen un perrito caliente y un número negativo para aquellos que no lo hacen es trivial. Debido a que hay muchos pesos en una red neuronal, lleva mucho tiempo encontrar los correctos para todas las neuronas de manera que todas las imágenes se clasifiquen correctamente. Simplemente hay demasiadas posibilidades. Además, dependiendo del conjunto de entrada, la red puede estar demasiado limitada al conjunto de datos específico, lo que significa que se centra demasiado estrechamente en el conjunto de datos y no puede generalizarse para reconocer imágenes fuera de él.
El proceso completo de formación de la red se basa en pasar los datos de entrada a través de la red varias veces. Cada pase toma la salida del anterior para hacer ajustes en pases futuros. La salida de cada pase se utiliza para proporcionar retroalimentación para mejorar el algoritmo a través de la retropropagación.
Una de las razones por las que la retropropagación tardó tanto en desarrollarse fue que la función requería que los ordenadores realizaran la multiplicación, lo que era bastante malo en las décadas de 1960 y 1970. A finales de la década de 1970, uno de los procesadores más potentes, el Intel 8086, podía calcular menos de un millón de instrucciones por segundo. * Para comparar,* el procesador que se ejecuta en el iPhone 12 es más de un millón de veces más potente que eso. *

APLICACIÓN GENERALIZADA
El aprendizaje profundo solo despegó en 2012, cuando Hinton y dos de sus estudiantes de Toronto demostraron que las redes neuronales profundas, entrenadas con retropropagación, vencieron a los sistemas de última generación en reconocimiento de imágenes casi a la mitad la tasa de error anterior. Debido a su trabajo y dedicación al campo, el nombre de Hinton se convirtió casi en sinónimo del campo del aprendizaje profundo. Ahora tiene más citas que los tres mejores investigadores de aprendizaje profundo combinados.
Después de este avance, el aprendizaje profundo comenzó a aplicarse en todas partes, con aplicaciones que incluían la clasificación de imágenes, la traducción del idioma y la comprensión del texto a voz, como lo usa Siri, por ejemplo. Los modelos de aprendizaje profundo pueden mejorar cualquier tarea que pueda abordarse mediante heurística, aquellas técnicas que se aplican para resolver algunas tareas que previamente fueron definidas por la experiencia o el pensamiento humano, incluidos juegos como Go, ajedrez y póquer, así como actividades como conducir coches. El aprendizaje profundo se utilizará cada vez más para mejorar el rendimiento de los sistemas informáticos con tareas como averiguar el orden en que los procesos deben ejecutarse o qué datos deben permanecer en una caché. Todas estas tareas pueden ser mucho más eficientes con los modelos de aprendizaje profundo. El almacenamiento será una gran aplicación de ello y, en mi opinión, el uso del aprendizaje profundo seguirá creciendo.
No es una coincidencia que el aprendizaje profundo despegue y funcionara mejor que la mayoría de los algoritmos de última generación: las redes neuronales multicapa tienen dos cualidades muy importantes. *
En primer lugar, expresan el tipo de funciones muy complicadas necesarias para resolver los problemas que tenemos que abordar. Por ejemplo, si quieres entender lo que está pasando con las imágenes, necesitas una función que recupere los píxeles y aplique una función complicada que los traduzca en texto o su representación al lenguaje humano. En segundo lugar, el aprendizaje profundo puede aprender con solo procesar datos, en lugar de necesitar una respuesta de retroalimentación. Estas dos cualidades lo hacen extremadamente poderoso, ya que muchos problemas, como la clasificación de imágenes, requieren muchos datos.
La razón por la que las redes neuronales profundas son tan buenas como son es que son equivalentes a los circuitos, y una neurona puede implementar fácilmente una función booleana. Por esa razón, una red lo suficientemente profunda puede simular un ordenador dado un número suficiente de pasos. Cada parte de una red neuronal simula la parte más simple de un procesador. Eso significa que las redes neuronales profundas son tan potentes como los ordenadores y, cuando se entrenan correctamente, pueden simular cualquier programa informático.
Actualmente, el aprendizaje profundo es un campo de batalla entre Google, Apple, Facebook y otras empresas de tecnología que tienen como objetivo satisfacer las necesidades de las personas en el mercado de consumo. Por ejemplo, Apple utiliza el aprendizaje profundo para mejorar sus modelos para Siri, y Google para su motor de recomendación en YouTube. Desde 2013, Hinton ha trabajado a tiempo parcial en Google en Mountain View, California, y Toronto, Canadá. Y, al momento de escribir este artículo en 2021, es el científico principal del equipo de Google Brain, posiblemente una de las organizaciones de investigación de IA más importantes del mundo.
Redes neuronales convolucionales
Hay muchos tipos de redes neuronales profundas, incluidas las redes neuronales convolucionales (CNN), las redes neuronales recurrentes (RNN) y las redes de memoria a corto plazo (LSTM), y cada una tiene propiedades diferentes. Por ejemplo, las redes neuronales recurrentes son redes neuronales profundas en las que las neuronas en las capas superiores se conectan de nuevo a las neuronas en las capas inferiores. Aquí, nos centraremos en las redes neuronales convolucionales, que son computacionalmente más eficientes y rápidas que la mayoría de las otras arquitecturas. * Son extremadamente relevantes, ya que se utilizan para la traducción de texto de última generación, el reconocimiento de imágenes y muchas otras tareas.

La primera vez que Yann LeCun revolucionó la inteligencia artificial fue un falso comienzo. * En 1995, había dedicado casi una década a lo que se consideraba una mala idea según muchos informáticos: que imitar algunas características del cerebro sería la mejor manera de mejorar los algoritmos de inteligencia artificial. Pero LeCun finalmente demostró que su enfoque podría producir algo sorprendentemente inteligente y útil.
En Bell Labs, LeCun trabajó en un software que simulaba cómo funciona el cerebro, más específicamente, cómo funciona la corteza visual. Bell Labs, una instalación de investigación propiedad de la entonces gigantesca AT&T, empleó a algunos de los eminentes informáticos de la época. Allí se desarrolló uno de los sistemas operativos Unix, que se convirtió en la base para Linux, macOS y Android. No solo eso, sino que también se desarrolló allí el transistor, la base de todos los chips de ordenador modernos, así como el láser y dos de los lenguajes de programación más utilizados hasta la fecha, C y C++. Era un centro de innovación, por lo que no fue una coincidencia que una de las arquitecturas de aprendizaje profundo más importantes naciera en el mismo laboratorio.

LeCun basó su trabajo en la investigación realizada por Kunihiko Fukushima, un investigador informático japonés. * Kunihiko creó un modelo de redes neuronales artificiales basado en cómo funciona la visión en el cerebro humano. La arquitectura se basó en dos tipos de células neuronales en el cerebro humano llamadas células simples y células complejas. Se encuentran en la corteza visual primaria, la parte del cerebro que procesa la información visual.
Las células simples son responsables de detectar características locales, como los bordes. Las células complejas agrupan los resultados que las células simples producen dentro de un área. Por ejemplo, una celda simple puede detectar un borde que puede representar una silla. Las células complejas agregan esa información informando al siguiente nivel superior lo que las células simples detectaron en la capa siguiente.
La arquitectura de una CNN se basa en un modelo en cascada de estos dos tipos de células, y se utiliza principalmente para tareas de reconocimiento de patrones. LeCun produjo el primer software que podía leer texto escrito a mano mirando muchos ejemplos diferentes usando este modelo de CNN. Con este trabajo, AT&T comenzó a vender las primeras máquinas capaces de leer escritura a mano en cheques. Para LeCun, esto marcó el comienzo de una nueva era en la que las redes neuronales se utilizarían en otros campos de la IA. Desafortunadamente, no iba a ser.

El mismo día que LeCun celebró el lanzamiento de máquinas bancarias que podían leer miles de cheques por hora, AT&T anunció que se estaba dividiendo en tres empresas diferentes, el resultado de una demanda antimonopolio del gobierno de los Estados Unidos. En ese momento, LeCun se convirtió en el jefe de investigación de un AT&T mucho más pequeño y fue dirigido a trabajar en otras cosas. En 2002, se fue y finalmente se convirtió en jefe del grupo de investigación de IA de Facebook.
LeCun continuó trabajando en redes neuronales, especialmente en redes neuronales convolucionales, y poco a poco el resto del mundo del aprendizaje automático se acercó a la tecnología. En 2012, algunos de sus estudiantes publicaron un artículo que demostraba el uso de CNN para clasificar los números de casas del mundo real mejor de lo que todos los algoritmos anteriores habían sido capaces de hacer. Desde entonces, las redes neuronales profundas han explotado en uso, y ahora la mayor parte de la investigación desarrollada en el aprendizaje automático se centra en el aprendizaje profundo. Las redes neuronales convolucionales se han extendido ampliamente y se han utilizado para vencer a la mayoría de los otros algoritmos para muchas aplicaciones, incluido el procesamiento del lenguaje natural y el reconocimiento de imágenes.
Los esfuerzos del equipo dieron sus frutos. En 2017, varias CNN procesaron todas las fotos subidas a Facebook. Uno de ellos identificó qué personas estaban en la imagen, y otro determinó si había objetos en la imagen. En ese momento, se subían alrededor de 800 millones de fotos al día, por lo que el rendimiento de las CNN era impresionante.
CÓMO FUNCIONAN LAS REDES NEURONALES CONVOLUNTIVAS
Una red neuronal convolucional (o CNN) es una red neuronal multicapa. Se nombra así porque contiene capas ocultas que realizan convoluciones. Una convolución es una función matemática que es la integral del producto de las dos funciones después de que una se invierte y se desplace. Para las imágenes, significa que estás ejecutando filtros en toda la imagen y produciendo imágenes con esos filtros.
En particular, la mayoría de las entradas a las CNN consisten en imágenes. *
En las capas que realizan la convolución, cada neurona camina a través de la imagen, multiplicando el número que representa cada píxel por el peso correspondiente en la neurona, generando una nueva imagen como salida.
Examinemos cómo una red neuronal convolucional clasifica las imágenes. Primero, necesitamos hacer una imagen de algo con lo que una red neuronal pueda trabajar. Una imagen es solo datos. Representamos cada píxel de la imagen como un número; en una imagen en blanco y negro, esto puede indicar lo negro que es ese píxel. La siguiente figura representa el número 8. En esta representación, 0 es blanco y 255 es completamente negro. Cuanto más cerca esté el número de 255, más oscuro es el píxel.


Piensa en cada neurona como un filtro que atraviesa toda la imagen. Cada capa puede tener múltiples neuronas. La siguiente figura muestra dos neuronas caminando por toda la imagen. La neurona roja camina primero a través de la imagen, y la neurona verde hace lo mismo produciendo una nueva imagen resultante.
Las imágenes resultantes pueden ir directamente a la siguiente capa de la red neuronal y son procesadas por esas neuronas. Las imágenes procesadas en una capa también se pueden procesar mediante un método llamado agrupación antes de pasar a la siguiente capa. La función de agrupar es simplificar los resultados de las capas anteriores. Esto puede consistir en obtener el número máximo que los píxeles representan en una determinada región (o vecindario) o sumar los números en un vecindario. Esto se hace en varias capas. Cuando una neurona atraviesa una imagen, la siguiente capa produce una imagen más pequeña truncando los datos. Este proceso se repite una y otra vez a través de capas sucesivas. Al final, la CNN produce una lista de números o un solo número, dependiendo de la aplicación.
En función del resultado, la imagen se puede clasificar en función de lo que el sistema está buscando. Por ejemplo, si el número resultante es positivo, la imagen se puede clasificar como que contiene un perrito caliente, y si el número resultante es negativo, entonces la imagen se clasifica como que no contiene un perrito caliente. Pero esto supone que sabemos cómo se ve cada neurona, es decir, cómo se ve el filtro para cada capa. Al principio, las neuronas son completamente aleatorias, y mediante el uso de la técnica de retropropagación, las neuronas se actualizan de tal manera que producen el resultado deseado.
Una CNN está entrenada mostrándole muchas imágenes etiquetadas con sus resultados: las etiquetas. Este conjunto se llama datos de entrenamiento. La red neuronal actualiza sus pesos, en función de si clasifica las imágenes correctamente o no, utilizando los algoritmos de retropropagation. Después de la etapa de entrenamiento, la red neuronal resultante es la que se utiliza para clasificar nuevas imágenes. A pesar de que las CNN se crearon en función del funcionamiento de la corteza visual, también se pueden usar en el texto, por ejemplo. Para ello, las entradas se traducen a una matriz para que coincidan con el formato de una imagen.
Hay un error de que las redes neuronales profundas son una caja negra, es decir, que no hay forma de saber lo que están haciendo. La cosa es que no hay forma de determinar para cada entrada, ya sea imagen, sonido o texto, cuál es la salida resultante, o si la red la va a clasificar correctamente. Pero eso no significa que no haya forma de determinar lo que hace cada capa en la red aneural.

De hecho, para las CNN, ves cómo se ven los filtros y qué tipo de imágenes activan cada capa. Los pesos de cada neurona se pueden interpretar como imágenes. La figura anterior muestra los filtros en diferentes capas y también algunos ejemplos de imágenes que activan estas capas. Por ejemplo, en la primera capa de un CNN multicapa, los filtros, o pesos, para las neuronas parecen bordes. Eso significa que los filtros se activarán cuando se encuentren los bordes. La segunda capa de filtros muestra que los tipos de imágenes que activan son un poco más complejos, con ojos, curvas y otras formas. La tercera capa se activa con imágenes como ruedas, perfiles de personas, pájaros y caras. Eso significa que en cada capa de la red neuronal, se filtran imágenes más complejas. La primera capa filtra y pasa la información a la siguiente capa que dice si un área contiene bordes o no. Luego, la siguiente capa utiliza esa información, y a partir de los bordes detectados, intentará encontrar ruedas, etc. La última capa identificará las categorías que los humanos quieren conocer: identificará, por ejemplo, si la imagen contiene un gato, un perrito caliente o un humano.
Google Brain: La primera red neuronal a gran escala
El cerebro seguro que no funciona cuando alguien programa reglas.Geoffrey Hinton*
Google Brain comenzó como un proyecto de investigación entre los empleados de Google Jeff Dean y Greg Corrado y el profesor de Stanford Andrew Ng en 2011. * Pero Google Brain se convirtió en mucho más que un simple proyecto. Al adquirir empresas como DeepMind y personal clave de IA como Geoffrey Hinton, Google se ha convertido en un jugador formidable en el avance de este campo.
Uno de los primeros hitos clave de las redes neuronales profundas fue el resultado de la investigación inicial dirigida por Ng cuando decidió procesar vídeos de YouTube y alimentarlos a una red neuronal profunda. * En el transcurso de tres días, alimentó 10 millones de vídeos de YouTube* a 1.000 ordenadores con 16 núcleos cada uno, utilizando los 16.000 procesadores informáticos como red neuronal para aprender las características comunes de estos vídeos. Después de recibir una lista de 20 000 objetos diferentes, el sistema reconoció imágenes de gatos y alrededor de otros 3.000 objetos. Comenzó a reconocer el 16 % de los objetos sin ninguna aportación de los humanos.
El mismo software que reconoció a los gatos fue capaz de detectar caras con una precisión del 81,7 % y partes del cuerpo humano con una precisión del 76,7 %. * Con solo los datos, la red neural aprendió a reconocer imágenes. Era la primera vez que se utilizaba una cantidad tan masiva de datos para entrenar una red neuronal. Esta se convertiría en la práctica estándar en los próximos años. Los investigadores hicieron una observación interesante: “Vale la pena señalar que nuestra red sigue siendo pequeña en comparación con la corteza visual humana, que es106veces mayor en términos de número de neuronas y sinapsis”. *
DeepMind: Aprender de la experiencia
Demis Hassabis fue un niño prodigio en el ajedrez, alcanzando el estándar de Maestro a los 13 años, el segundo jugador mejor valorado en la categoría Mundial Sub-14, y también “cotó en la Serie Mundial de Póquer seis veces, incluso en el Evento Principal”. * En 1994 a los 18 años, comenzó su carrera en juegos de ordenador codiseñando y programando el clásico juego Theme Park, que vendió millones de copias. * Luego se convirtió en el jefe de desarrollo de IA para un juego icónico llamado Black & White en Lionhead Studios. Hassabis obtuvo su doctorado en neurociencia cognitiva en el University College de Londres en 2009.

En 2010, Hassabis cofundó DeepMind en Londres con la misión de “resolver inteligencia” y luego usar esa inteligencia para “solstar todo lo demás”. Al principio de su desarrollo, DeepMind se centró en algoritmos que dominaban los juegos, empezando por los juegos desarrollados para Atari. * Google adquirió DeepMind en 2014 por 525 millones de dólares.
DEEPMIND JUEGA A ATARI
Para ayudar al programa a jugar, el equipo de DeepMind desarrolló un nuevo algoritmo, Deep Q-Network (DQN), que aprendió de la experiencia. Empezó a jugar juegos como el famoso juego Breakout, interpretando el vídeo y produciendo un comando en el joystick. Si el comando produjo una acción en la que el jugador obtuvo una puntuación, entonces el software de aprendizaje reforzó esa acción. La próxima vez que juegue, es probable que haga la misma acción. Es el aprendizaje de refuerzo, pero con una red neuronal profunda para determinar la calidad de una combinación de estado-acción. El DNN ayuda a determinar qué acción tomar dado el estado del juego, y el algoritmo aprende con el tiempo después de jugar algunos juegos y determinar las mejores acciones a tomar en cada punto.
Por ejemplo, en el caso de Breakout,* después de jugar cien juegos, el software seguía siendo bastante malo y se perdía la pelota a menudo. Pero siguió jugando, y después de unas horas, 300 juegos, el software mejoró y jugó con la capacidad humana. Podría devolver la pelota y mantenerla viva durante mucho tiempo. Después de que lo dejaron jugar durante unas horas más, 500 juegos, se volvió mejor que el humano promedio, aprendiendo a hacer un truco llamado túnel, que implica enviar sistemáticamente la pelota a las paredes laterales para que rebote en la parte superior, requiriendo menos trabajo y ganando más recompensa. El mismo algoritmo de aprendizaje funcionó no solo en Breakout, sino también para la mayoría de los 57 juegos en los que DeepMind probó la técnica, alcanzando un nivel sobrehumano para la mayoría de ellos.

Sin embargo, el algoritmo de aprendizaje no funcionó bien para todos los juegos. Mirando al final de la lista, el software obtuvo una puntuación de cero en la Venganza de Montezuma. El software DQN de DeepMind no tiene éxito en este juego porque el jugador necesita entender conceptos de alto nivel que la gente aprende a lo largo de su vida. Por ejemplo, si miras el juego, sabes que estás controlando al personaje y que las escaleras son para escalar, las cuerdas son para balancearse, las llaves son probablemente buenas y el cráneo es probablemente malo.
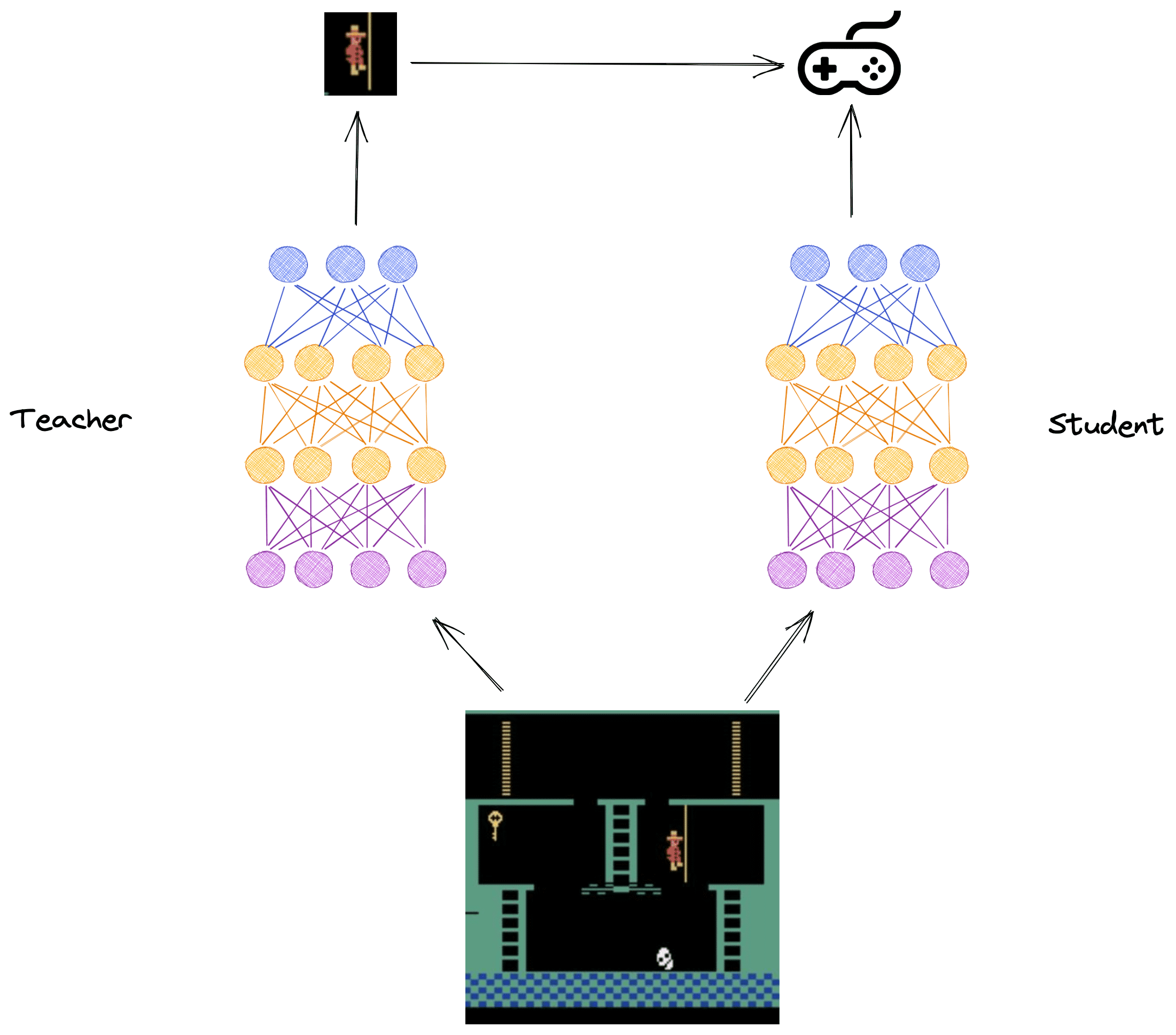
DeepMind mejoró el sistema dividiendo el problema en tareas más simples. Si el software pudiera resolver cosas como “saltar a través de la brecha”, “llevar a la escalera” y “pasar el cráneo y recoger la llave”, entonces podría resolver el juego y rendir bien en la tarea. Para atacar este problema, DeepMind creó dos redes neuronales: el profesor y el alumno. El profesor es responsable de aprender y producir estos subproblemas. El profesor envía estos subproblemas a otra red neuronal llamada el estudiante. El estudiante toma medidas en el juego e intenta maximizar la puntuación, pero también intenta hacer lo que el profesor le dice. A pesar de que fueron entrenados con los mismos datos que el antiguo algoritmo, además de alguna información adicional, la comunicación entre el profesor y el estudiante permitió que la estrategia y la comunicación surgieran con el tiempo, ayudando al agente a aprender a jugar el juego.
AlphaGo: Derrotando a los mejores jugadores de Go
En la introducción, discutimos la competencia Go entre Lee Sedol y AlphaGo. Bueno, DeepMind desarrolló AlphaGo con el objetivo de jugar Go contra los Grandmasters. Octubre de 2015 fue la primera vez que el software venció a un humano en Go, un juego con10170posiciones, más posiciones posibles que el número de movimientos en el ajedrez o incluso el número total de átomos en el universo (alrededor1080). De hecho, si cada átomo del universo fuera un universo en sí, habría menos átomos que el número de posiciones en un juego Go.
En muchos países, como Corea del Sur y China, el Go se considera un juego nacional, como el fútbol y el baloncesto en los EE. UU., y estos países tienen muchos jugadores profesionales del Go, que entrenan a partir de los 6 años. * Si estos jugadores muestran promesa en el juego, cambian de una escuela normal a una escuela especial de Go donde juegan y estudian Go durante 12 horas al día, 7 días a la semana. Viven con su Go Master y otros hijos prodigios. Por lo tanto, es un asunto serio que un programa informático desafíe a estos jugadores.
Hay alrededor de 2.000 jugadores profesionales de Go en el mundo, junto con aproximadamente 40 millones de jugadores casuales. En una entrevista en el Google Campus,* Hassabis compartió: “Sabíamos que Go era mucho más difícil que el ajedrez”. Describe cómo pensó inicialmente en construir AlphaGo de la misma manera que se construyó Deep Blue, es decir, construyendo un sistema que hiciera una búsqueda de fuerza bruta con un conjunto de reglas hechas a mano.
Pero se dio cuenta de que esta técnica nunca funcionaría, ya que el juego es muy contextual, lo que significa que no había forma de crear un programa que pudiera determinar cómo una parte del tablero afectaría a otras partes debido al gran número de posibles estados. Al mismo tiempo, se dio cuenta de que si hubiera creado un algoritmo para vencer a los jugadores maestros en Go, entonces probablemente habría hecho un avance significativo en IA, más significativo que Deep Blue.
Go no solo es difícil porque el juego tiene un número astronómico de posibilidades, sino que para que un programa sea bueno jugando a Go, necesita determinar el mejor siguiente movimiento. Para averiguarlo, el software necesita determinar si una posición es buena o no. No puede jugar todas las posibilidades hasta el final porque había demasiadas. La sabiduría convencional pensó que era imposible determinar el valor de un determinado estado de juego para Go. Es mucho más simple hacer esto para el ajedrez. Por ejemplo, puede codificar cosas como la estructura de peones y la movilidad de las piezas, que son técnicas que los Grandes Maestros utilizan para determinar si una posición es buena o mala. En Go, por otro lado, todas las piezas son iguales. Incluso una sola piedra puede modificar el resultado del juego, por lo que cada una tiene un profundo impacto en el juego.
Lo que hace que Go sea aún más difícil es que es un juego constructivo en lugar de uno destructivo. En el ajedrez, empiezas con todas las piezas del tablero y te las quitas mientras juegas, lo que hace que el juego sea más sencillo. Cuanto más juegues, menos posibilidades habrá para los próximos movimientos. Go, sin embargo, comienza con un tablero vacío, y agregas piezas, lo que hace que sea más difícil de analizar. En el ajedrez, si analizas un juego intermedio complicado, puedes evaluar la situación actual, y eso lo dice todo. Para analizar un juego intermedio en Go, tienes que proyectar en el futuro para examinar la situación actual del tablero, lo que hace que sea mucho más difícil de analizar. En realidad, Go se trata más de la intuición y el instinto que del cálculo como el ajedrez.
Al describir el algoritmo que AlphaGo produjo, Hassabis dijo que no se limita a regurgitar las ideas humanas y las copia. Realmente viene con ideas originales. Según él, Go es un arte objetivo porque a cualquiera se le ocurre un movimiento original, pero se puede medir si ese movimiento o idea fue fundamental para ganar el juego. A pesar de que Go se ha jugado a nivel profesional durante 3.000 años, AlphaGo creó nuevas técnicas e influyó directamente en la forma en que la gente jugaba porque AlphaGo era estratégico y parecía humano.
EL FUNCIONAMIENTO DE ALPHAGO
DeepMind desarrolló AlphaGo principalmente con dos redes neuronales. * El primero, la Red de Políticas, calcula la probabilidad del siguiente movimiento para un jugador profesional dado el estado de la junta. En lugar de buscar los próximos 200 movimientos, la Red de Políticas solo busca los próximos cinco a diez. Al hacerlo, reduce el número de posiciones que AlphaGo tiene que buscar para encontrar cuál es el siguiente mejor movimiento.
Inicialmente, AlphaGo se entrenó utilizando alrededor de 100.000 juegos de Go de Internet. Pero una vez que pudo reducir la búsqueda del siguiente movimiento, AlphaGo jugó contra sí mismo millones de veces y mejoró a través del aprendizaje de refuerzo. El programa aprendió a través de sus propios errores. Si ganara, sería más probable que hiciera esos movimientos en el próximo juego. Con esa información, creó su propia base de datos de millones de juegos del sistema jugando contra sí mismo.
Luego, DeepMind entrenó una segunda red neuronal, la Value Network, que calculó la probabilidad de que un jugador ganara en función del estado del tablero. Se produce 1 para la victoria negra, 0 para el blanco y 0,5 para un empate. Juntas, estas dos redes convirtieron lo que parecía un problema intratable en uno manejable. Transformaron el problema de jugar a Go en un problema similar de resolver un juego de ajedrez. La Red de Políticas proporciona los siguientes diez movimientos probables, y la Red de Valor da la puntuación de un estado de la junta. Dadas estas dos redes, el algoritmo para encontrar los mejores movimientos, la búsqueda del árbol de Monte Carlo, similar a la utilizada para jugar al ajedrez, es decir, la búsqueda mínima máxima descrita anteriormente, utiliza las probabilidades para explorar el espacio de posibilidades.
EL PARTIDO
AlphaGo jugó como el mejor jugador del mundo, Lee Sedol, una leyenda del juego que había ganado más de 18 títulos mundiales. En juego estaba en 1 millón de dólares de recompensa.
AlphaGo jugó movimientos inimaginables, cambiando la forma en que la gente jugaría a Go en los próximos años. El campeón europeo, Fen Hui, le dijo a Hassabis que su mente estaba libre de los grilletes de la tradición después de ver las innovadoras obras de AlphaGo; ahora consideraba pensamientos impensables y no estaba limitado por la sabiduría recibida que lo había ligado durante décadas.
“Estaba profundamente impresionado”, dijo Ke Jie a través de un intérprete después del partido. Refiriéndose a un tipo de movimiento que implica dividir las piedras de un oponente, agregó: “Hubo un corte que me sorprendió bastante, porque era un movimiento que nunca ocurriría en un partido de Go de humano a humano”. * Jie, el actual jugador de Go número uno del mundo, declaró: “La humanidad ha jugado al Go durante miles de años y, sin embargo, como nos ha demostrado la IA, ni siquiera hemos rayado la superficie”. Continuó: “La unión de los jugadores humanos y informáticos marcará el comienzo de una nueva era. Juntos, el hombre y la IA pueden encontrar la verdad de Go”. *
ALPHAGO ZERO
El equipo de DeepMind no se detuvo después de ganar contra el mejor jugador del mundo. Decidieron mejorar el software, por lo que fusionaron las dos redes de neuronas profundas, las redes de políticas y valor, creando AlphaGo Zero. “La fusión de estas funciones en una sola red neuronal hizo que el algoritmo fuera más fuerte y mucho más eficiente”, dijo David Silver, el investigador principal de AlphaGo. AlphaGo Zero eliminó muchas redundancias entre las redes de dos neuronas. La probabilidad de añadir una pieza a una posición (Policy Network) contiene la información de quién podría ganar el juego (Value Network). Si solo hay una posición para que el jugador coloque una pieza, podría significar que el jugador está acorralado y tiene pocas posibilidades de ganar. O, si el jugador puede colocar una pieza en cualquier lugar del tablero, eso probablemente significa que el jugador está ganando porque no importa dónde coloque la siguiente pieza en el tablero. Y debido a que la fusión de las redes eliminó estas redundancias, la red neuronal resultante era más pequeña, lo que la hacía mucho menos compleja y, por lo tanto, más eficiente. La red tenía menos pesos y requería menos entrenamiento para averiguarlo. “Todavía requería una gran cantidad de potencia informática: cuatro de los chips especializados llamados unidades de procesamiento de tensores (TPU), que Hassabis estimó en 25 millones de dólares de hardware. Pero sus predecesores usaron diez veces ese número. También se entrenó en días en lugar de meses. La implicación es que “los algoritmos importan mucho más que la informática o los datos disponibles”, dijo Silver. *
Los críticos señalan que lo que hace AlphaGo en realidad no es aprender porque si hicieras que el agente jugara el juego con las mismas reglas pero cambiaras el color de las piezas, entonces el programa estaría confundido y funcionaría terriblemente. Los humanos pueden jugar bien si hay cambios menores en el juego. Pero eso se puede resolver entrenando el software con diferentes juegos, así como con diferentes piezas de colores. DeepMind hizo que sus algoritmos se generalizaran para otros juegos como Atari utilizando una técnica llamada consolidación sináptica. Sin este nuevo método, cuando un agente aprende a jugar el juego por primera vez, el agente satura las conexiones neuronales con el conocimiento sobre cómo jugar el primer juego. Luego, cuando el agente comienza a aprender a jugar una variación del juego o un juego diferente, todas las conexiones se destruyen para aprender a jugar el segundo juego, produciendo un olvido catastrófico.
Si una red neuronal simple está entrenada para jugar al Pong controlando la paleta a la izquierda, entonces después de que aprenda a jugar el juego, el agente siempre ganará, obteniendo una puntuación de 20 a 0. Si cambias el color de la paleta de verde a negro, el agente sigue controlando la misma paleta, pero siempre perderá la pelota. Termina perdiendo 20 a 0, mostrando un fracaso catastrófico. DeepMind resolvió esto inspirándose en cómo funciona el cerebro de un ratón y, presumiblemente, también de cómo funciona el cerebro humano. En el cerebro, hay un proceso llamado consolidación sináptica. Es el proceso en el que el cerebro solo protege las conexiones neuronales que se forman cuando se aprende una nueva habilidad en particular.

Inspirándose en la biología, DeepMind desarrolló un algoritmo que hace lo mismo. Después de jugar un juego, identifica y protege solo las conexiones neuronales que son las más importantes para ese juego. Eso significa que cada vez que el agente comienza a jugar un nuevo juego, las neuronas sobrante se pueden usar para aprender un nuevo juego y, al mismo tiempo, se conserva el conocimiento que se utilizó para jugar el juego antiguo, eliminando el olvido catastrófico. Con esta técnica, DeepMind demostró que los agentes podían aprender a jugar diez juegos de Atari sin olvidar cómo jugar a los viejos a nivel sobrehumano. La misma técnica se puede utilizar para hacer que AlphaGo aprenda a jugar diferentes variaciones del juego Go.
OpenAI
OpenAI, un instituto de investigación iniciado por multimillonarios de tecnología como Elon Musk, Sam Altman, Peter Thiel y Reid Hoffman, tuvo un nuevo desafío. OpenAI se inició para avanzar en la inteligencia artificial y evitar que la tecnología se vuelva peligrosa. En 2016, dirigidos por el CTO y cofundador, Greg Brockman, comenzaron a buscar en Twitch, una comunidad de juegos por Internet, para encontrar los juegos más populares que tenían una interfaz con la que un programa de software pudiera interactuar y que se ejecutaban en el sistema operativo Linux. Eligieron Dota 2. La idea era hacer un programa de software que pudiera vencer al mejor jugador humano, así como a los mejores equipos del mundo, un objetivo elevado. Por un amplio margen, Dota 2 sería el juego más difícil en el que la IA vencería a los humanos.
A primera vista, Dota 2 puede parecer menos cerebral que Go y ajedrez debido a sus orcos y criaturas. El juego, sin embargo, es mucho más difícil que esos juegos de estrategia porque el tablero en sí y el número de movimientos posibles son mucho mayores que los juegos anteriores. No solo eso, sino que hay alrededor de 110 héroes, y cada uno tiene al menos cuatro movimientos. El número promedio de movimientos posibles por turno para el ajedrez es de alrededor de 20 y para Go, alrededor de 200. Dota 2 tiene un promedio de 1000 movimientos posibles por cada octavo de segundo, y el partido promedio dura alrededor de 45 minutos. Dota 2 no es una broma.

Su primer desafío fue vencer a los mejores humanos en un partido individual. Eso significaba que una máquina solo jugaba contra un solo humano que controlaba a su propia criatura. Esa es una hazaña mucho más fácil que un ordenador jugando contra un equipo de cinco humanos (5v5) porque jugar uno a uno es un juego más estratégico y un desafío mucho más difícil para los humanos. Con un equipo, un jugador podría defenderse y otro atacar al mismo tiempo, por ejemplo.
Para vencer a los mejores humanos en este juego, OpenAI desarrolló un sistema llamado Rapid. En este sistema, los agentes de IA jugaron contra sí mismos millones de veces al día, utilizando el aprendizaje de refuerzo para entrenar una red neuronal multicapa, una LSTM específicamente, para que pudiera aprender los mejores movimientos con el tiempo. Con todo este entrenamiento, en agosto del año siguiente, los agentes de OpenAI derrotaron a los jugadores de bestDota 2 en partidos uno a uno y permanecieron invictos contra ellos.

OpenAI se centró en la versión más difícil del juego: 5v5. El nuevo agente se llamó acertadamente OpenAI Five. Para entrenarlo, OpenAI volvió a utilizar su sistema Rapid, jugando el equivalente a 180 años de Dota 2 al día. Corrió sus simulaciones utilizando el equivalente a 128 000 procesadores informáticos y 256 GPU. La capacitación se centró en actualizar una enorme red de memoria a corto plazo con los juegos y aplicar el aprendizaje de refuerzo. OpenAI Five recibe una cantidad impresionante de información: 20 000 números que representan el estado de la junta y lo que los jugadores están haciendo en un momento dado. *

En enero de 2018, OpenAI comenzó a probar su software contra bots, y su agente de IA ya estaba ganando contra algunos de ellos. En agosto del mismo año, OpenAI Five venció a algunos de los mejores equipos humanos en un partido de 5 contra 5, aunque con algunas limitaciones a las reglas.
Por lo tanto, el equipo de OpenAI decidió jugar contra el mejor equipo del mundo en la mayor competición de Dota 2, The International, en Vancouver, Canadá. A finales de agosto, los agentes de IA jugaron contra el mejor equipo del mundo frente a una gran audiencia en un estadio, y cientos de miles de personas vieron el partido a través de la transmisión. En un partido muy competitivo, perdió contra el equipo humano. Pero en menos de un año, en abril de 2019, OpenAI Five venció al mejor equipo del mundo en dos partidos consecutivos en el International. *
Software 2.0
Los lenguajes informáticos del futuro estarán más preocupados por los objetivos y menos por los procedimientos especificados por el programador.Marvin Minsky*
El paradigma Software 2.0 comenzó con el desarrollo del primer lenguaje de aprendizaje profundo, TensorFlow.
Al crear redes neuronales profundas, los programadores escriben solo unas pocas líneas de código y hacen que la red neuronal aprenda el programa en sí en lugar de escribir código a mano. Este nuevo estilo de codificación se llama Software 2.0 porque antes del auge del aprendizaje profundo, la mayoría de los programas de IA estaban escritos a mano en lenguajes de programación como Python y JavaScript. Los humanos escribieron cada línea de código y también determinaron todas las reglas del programa. En contraste, con la aparición de técnicas de aprendizaje profundo, la nueva forma en que los codificadores programan estos sistemas es especificando el objetivo del programa, como ganar un juego Go, o proporcionando datos con la entrada y salida adecuadas, como alimentar a las imágenes del algoritmo de gatos con etiquetas de “gato” y otras imágenes sin gatos con etiquetas “no gato”.
Basado en el objetivo, el programador escribe el esqueleto del programa definiendo la(s) arquitectura(es) de la red neuronal. Luego, el programador utiliza el hardware del ordenador para encontrar la red neuronal exacta que mejor realiza el objetivo especificado y le da datos para entrenar a la red neuronal. Con el software tradicional, Software 1.0, la mayoría de los programas se almacenan como código escrito por un programador que puede abarcar entre miles y mil millones de líneas de código. Por ejemplo, toda la base de código de Google tiene alrededor de dos mil millones de líneas de código. * Pero en el nuevo paradigma, el programa se almacena en la memoria como los pesos de la arquitectura neuronal con pocas líneas de código escritas por programadores. Hay desventajas en este nuevo enfoque: los desarrolladores de software a veces tienen que elegir entre usar software que entienden, pero que solo funciona el 90 % del tiempo, o un programa que funciona bien en el 99 % de los casos, pero no se entiende tan bien.
TENSORFLOW
Algunos lenguajes se crearon solo para escribir Software 2.0, es decir, lenguajes de programación para ayudar a construir, entrenar y ejecutar estas redes neuronales. El más conocido y ampliamente utilizado es TensorFlow. Desarrollado por Google y lanzado internamente en 2015, ahora alimenta productos de Google como Smart Reply y Google Photos, pero también se puso a disposición de desarrolladores externos. Ahora es más popular que el sistema operativo Linux por algunas métricas. Fue ampliamente utilizado por desarrolladores, nuevas empresas y otras grandes empresas para todo tipo de tareas de aprendizaje automático, incluida la traducción del inglés al chino y la lectura de textos escritos a mano. TensorFlow se utiliza para crear, entrenar e implementar una red neuronal para realizar diferentes tareas. Pero para entrenar la red resultante, el desarrollador debe alimentarla con datos y definir el objetivo para el que la red neuronal optimiza. Esto es tan importante como definir la red neuronal.
LA IMPORTANCIA DE LOS BUENOS DATOS DE ENTRENAMIENTO
Debido a que una gran parte del programa son los datos que se le suministran, existe una creciente preocupación de que los conjuntos de datos utilizados para estas redes representen todos los posibles escenarios en los que el programa pueda encontrarse. Los datos se han vuelto esenciales para que el software funcione como se esperaba. Uno de los problemas es que a veces los datos pueden no representar todos los casos de uso que un programador quiere cubrir al desarrollar la red neural. Y es posible que los datos no representen los escenarios más importantes. Por lo tanto, el tamaño y la variedad del conjunto de datos se han vuelto cada vez más importantes para que las redes neuronales funcionen como se esperaba.
Por ejemplo, digamos que quieres una red neuronal que cree una caja delimitadora alrededor de los coches en la carretera. Los datos deben cubrir todos los casos. Si hay un reflejo de un coche en un autobús, entonces los datos no deberían tener etiquetado como un coche en la carretera. Para que la red neuronal aprenda eso, el programador necesita tener suficientes datos que representen este caso de uso. O digamos que hay cinco coches en un portacoches. ¿Debería el software crear una caja delimitadora para cada uno de los automóviles o solo para el portador del automóvil? De cualquier manera, el programador necesita suficientes ejemplos de estos casos en el conjunto de datos.
Otro ejemplo es si los datos de entrenamiento del coche vienen con muchos datos recopilados en ciertas condiciones de iluminación o con un vehículo específico. Entonces, si esos mismos algoritmos se encuentran con un vehículo con una forma diferente o con una iluminación diferente, el algoritmo puede comportarse de manera diferente. Un ejemplo que le sucedió a Tesla fue cuando el software de conducción autónoma estaba activado y el software no se dio cuenta del remolque frente al coche. El lado blanco del remolque del tractor contra un cielo brillantemente iluminado era difícil de detectar. El accidente provocó la muerte del conductor. *
El etiquetado, es decir, crear el conjunto de datos y anotarlo con la información correcta, es un proceso iterativo importante que requiere tiempo y experiencia para que funcione correctamente. Los datos deben capturarse y limpiarse. No es algo hecho una vez y luego está completo. Más bien, es algo que evoluciona.
EL GRANJERO JAPONÉS DE PEPINOS
TensorFlow no solo ha sido utilizado por desarrolladores, nuevas empresas y grandes corporaciones, sino también por individuos. Una historia sorprendente es de un agricultor japonés de pepinos. Un ingeniero automotriz, Makoto Koike, ayudó a sus padres a clasificar los pepinos por tamaño, forma, color y otros atributos en su pequeña granja familiar en la pequeña ciudad de Kosai. Durante años, clasificaron sus pepinillos manualmente. Sucede que los pepinos en Japón tienen precios diferentes dependiendo de sus características. Por ejemplo, los pepinos más coloridos y los que tienen muchas garradores son más caros que otros. Los agricultores dejan de lado los pepinos que son más caros para que se les pague de manera justa por su cosecha.
El problema es que es difícil encontrar trabajadores para clasificarlos durante la temporada de cosecha, y no hay máquinas que se vendan a los pequeños agricultores para ayudar con la clasificación de pepinos. Son demasiado caros o no proporcionan las capacidades que las pequeñas granjas necesitan. Los padres de Makoto separaron los pepinos a mano, lo cual es tan difícil como cultivarlos y lleva meses. La madre de Makoto solía pasar ocho horas al día clasificándolos. Así que, en 2015, después de ver cómo AlphaGo derrotó a los mejores jugadores de Go, Makoto tuvo una idea. Decidió usar el mismo lenguaje de programación, TensorFlow, para desarrollar una máquina de clasificación de pepinos.
Para ello, tomó 7.000 fotos de pepinos cosechados en la granja de su familia. Luego, etiquetó las imágenes con las propiedades que tenía cada pepino, añadiendo información sobre su color, forma, tamaño y si contenían pinchos. Utilizó una arquitectura de red neuronal popular y la entrenó con las fotos que tomó. En ese momento, Makoto no entrenó la red neuronal con los servidores informáticos que Google ofrecía porque cobraban por el tiempo utilizado. En su lugar, entrenó la red usando su ordenador de escritorio de baja potencia. Por lo tanto, para entrenar su herramienta de manera oportuna, convirtió las imágenes a un tamaño más pequeño de 80×80 píxeles. Cuanto más pequeño sea el tamaño de las imágenes, más rápido será entrenar la red neuronal porque la red neuronal también es más pequeña. Pero incluso con la baja resolución, le llevó tres días entrenar su red neuronal.
Después de todo el trabajo, “cuando hice una validación con las imágenes de prueba, la precisión de reconocimiento superó el 95 %. Pero si aplicas el sistema con casos de uso real, la precisión cae a alrededor del 70 %. Sospecho que el modelo de red neuronal tiene el problema de “sobreajuste”, declaró Makoto. *
El sobreajuste, también llamado sobreentrenamiento, es el fenómeno cuando se crea un modelo de aprendizaje automático y solo funciona para los datos de entrenamiento.
Makoto creó una máquina que pudo ayudar a sus padres a clasificar los pepinos en diferentes formas, colores, longitud y nivel de distorsión. No pudo averiguar si los pepinos tenían muchas pinchatas o no debido a las imágenes de baja resolución utilizadas para el entrenamiento. Pero la máquina resultante resultó ser muy útil para su familia y cortó el tiempo que pasaron clasificando manualmente sus productos.
La misma tecnología construida por una de las empresas más grandes del mundo y utilizada para alimentar sus muchos productos también fue utilizada por un pequeño agricultor del otro lado del mundo. TensorFlow democratizó el acceso para que muchas personas pudieran desarrollar sus propios modelos de aprendizaje profundo. No será sorprendente encontrar muchos más “Makotos” por ahí.
ERRORES 2.0
En el Software 1.0, los problemas, llamados errores, ocaieron principalmente porque una persona escribía una lógica que no tenía en cuenta los casos de borde ni manejaba todos los escenarios posibles. Pero en la pila de Software 2.0, los errores son muy diferentes porque los datos pueden confundir a la red neuronal.
Un ejemplo de tal error fue cuando la autocorrección para iOS comenzó a usar un carácter extraño “#?” para reemplazar la palabra “yo” al enviar un mensaje. El sistema operativo corrigió automáticamente por error la ortografía de I porque, en algún momento, los datos que recibió le enseñaron a hacerlo. El modelo aprendió que “#?” era la ortografía correcta de acuerdo con los datos. Tan pronto como alguien envió “yo”, el modelo pensó que era importante arreglarlo y reemplazarlo en todas partes. El error se propagó como un virus, llegando a millones de iPhones. Dado lo rápidos e importantes que pueden ser estos errores, es extremadamente importante que los datos y los programas estén bien probados, asegurándose de que estos casos de borde no hagan que los programas fallen.
Duelo de redes neuronales
Lo que no puedo crear, no lo entiendo.Richard Feynman*
Uno de los desarrollos más importantes de la última década en el aprendizaje profundo son las redes adversarias generativas, desarrolladas por Ian Goodfellow. Esta nueva tecnología también se puede utilizar para malas intenciones, como para generar imágenes y vídeos falsos.
REDES ADVERSARIAS GENERATIVAS

GAN, o red adversaria generativa, es una clase de marco de aprendizaje automático donde dos redes neuronales juegan un juego de gato y ratón. Uno crea imágenes falsas que se parecen a las reales, y el otro decide si son reales.
Las redes adversarias generativas (GAN), a veces llamadas redes generativas, crearon estas imágenes falsas. El equipo de investigación de Nvidia utilizó esta nueva técnica al alimentar miles de fotos de celebridades a una red neuronal. La red neuronal, a su vez, ha producido miles de imágenes, como las de arriba, que se parecen a las caras famosas. Parecen reales, pero las máquinas los crearon. Los GAN permiten a los investigadores crear imágenes que se parezcan a las reales compartiendo muchas características de las imágenes que se alimentaba a la red neuronal. Se pueden alimentar con fotografías de objetos desde mesas hasta animales, y después de ser entrenado, produce imágenes que se parecen a los originales.

Para que el equipo de Nvidia generara estas imágenes, creó dos redes neuronales. Uno que produjo las imágenes y el otro que determinó si eran reales o falsas. La combinación de estas dos redes neuronales produjo una GAN, o red adversaria generativa. Juegan a un juego de gato y ratón, donde uno crea imágenes falsas que se parecen a las reales, y el otro decide si son reales. ¿Esto te recuerda algo? La prueba de Turing. Piensa en las redes como jugando al juego de adivinanzas de si las imágenes son reales o falsas.
Después de que se haya entrenado el GAN, una de las redes neuronales crea imágenes falsas que se parecen a las reales utilizadas en el entrenamiento. Las imágenes resultantes se ven exactamente igual que las fotos de la gente real. Esta técnica puede generar grandes cantidades de datos falsos que pueden ayudar a los investigadores a predecir el futuro o incluso a construir mundos simulados. Es por eso que para Yann LeCun, Director de Facebook AI Research, “Generative Adversarial Networks es la idea más interesante de los últimos diez años en el aprendizaje automático“. * Los GAN serán útiles para crear imágenes y tal vez crear simulaciones de software del mundo real, donde los desarrolladores pueden entrenar y probar otros tipos de software. Por ejemplo, las empresas que escriben software de conducción autónoma para automóviles pueden entrenar y comprobar su software en mundos simulados. Hablaré de esto en detalle más adelante.
Estos mundos y situaciones simulados ahora están hechos a mano por desarrolladores, pero algunos creen que todos estos escenarios serán creados por GAN en el futuro. Los GAN generan nuevas imágenes y vídeos a partir de datos muy comprimidos. Por lo tanto, podrías usar las dos redes neuronales de un GAN para guardar datos y luego restablecerlos. En lugar de comprimir tus archivos, podrías usar una red neuronal para comprimirla y la otra para generar los vídeos o imágenes originales. No es coincidencia que en el cerebro humano parte del aparato utilizado para la imaginación sea el mismo que el utilizado para el recuerdo de la memoria. Demis Hassabis, el fundador de DeepMind, publicó un artículo* que “mostraba sistemáticamente por primera vez que los pacientes con daños en su hipocampo, que se sabe que causan amnesia, tampoco podían imaginarse en nuevas experiencias”. * El hallazgo estableció un vínculo entre el proceso constructivo de la imaginación* y el proceso reconstructivo de recuerdo episódico de la memoria. * Hay más detalles sobre esto más adelante.

EL CREADOR DE GANS
A Ian Goodfellow, el creador de GAN, se le ocurrió la idea en un bar de Montreal cuando estaba con otros investigadores discutiendo lo que implica la creación de fotografías. El plan inicial era entender las estadísticas que determinaban qué creaban las fotos y luego alimentarlas a una máquina para que pudiera producir las imágenes. Goodfellow pensó que la idea nunca funcionaría porque se necesitan demasiadas estadísticas. Así que pensó en usar una herramienta, una red neuronal. Podría enseñar a las redes neuronales a descubrir las características subyacentes de las imágenes alimentadas a la máquina y luego generar otras nuevas.

Goodfellow luego añadió dos redes neuronales para que pudieran construir juntos fotografías realistas. Uno creó imágenes falsas y el otro determinó si eran reales. La idea era que una de las redes adversarias enseñara a la otra a producir imágenes que no se podían distinguir de las reales.
La misma noche que se le ocurrió la idea, se fue a casa, un poco borracho, y se quedó despierto esa noche codificando el concepto inicial de un GAN en su portátil. Funcionó en el primer intento. Unos meses más tarde, él y algunos otros investigadores publicaron el artículo seminal sobre GAN en una conferencia. * El GAN entrenado usó dígitos escritos a mano de un conocido conjunto de imágenes de entrenamiento llamado MNIST.*
En los años siguientes, se publicaron cientos de artículos utilizando la idea de GAN para producir no solo imágenes, sino también vídeos y otros datos. Ahora en Google Brain, Goodfellow dirige un grupo que está haciendo que el entrenamiento de estas dos redes neuronales sea muy fiable. El resultado de este trabajo son servicios que son mucho mejores para generar imágenes y sonidos de aprendizaje, entre otras cosas. “Los modelos aprenden a entender la estructura del mundo”, dice Goodfellow. “Y eso puede ayudar a los sistemas a aprender sin que se les diga explícitamente”.

Los GAN podrían eventualmente ayudar a las redes neuronales a aprender con menos datos, generando más imágenes sintéticas que luego se utilizan para identificar y crear mejores redes neuronales. Recientemente, un grupo de investigadores de Dropbox mejoró su escáner de documentos móvil mediante el uso de imágenes generadas sintéticamente. Los GAN produjeron nuevas imágenes de palabras que, a su vez, se utilizaron para entrenar la red neuronal.
Y eso es solo el comienzo. Los investigadores creen que se puede aplicar la misma técnica para desarrollar datos artificiales que se pueden compartir abiertamente en Internet sin revelar la fuente principal, asegurándose de que los datos originales permanezcan privados. Esto permitiría a los investigadores crear y compartir información de atención médica sin compartir datos confidenciales sobre los pacientes.
Los GAN también muestran una promesa para predecir el futuro. Puede sonar como ciencia ficción ahora, pero eso podría cambiar con el tiempo. LeCun está trabajando en el software de escritura que puede generar vídeo de situaciones futuras basado en el vídeo actual. Él cree que la inteligencia humana radica en el hecho de que podemos predecir el futuro y, por lo tanto, los GAN serán una fuerza poderosa para los sistemas de inteligencia artificial en el futuro. *
LA PRUEBA DEL PARADOJA DE CUMPLEAÑOS
A pesar de que los GAN están generando nuevas imágenes y sonidos, algunas personas preguntan si los GAN generan nueva información. Una vez que un GAN está capacitado en una recopilación de datos, ¿puede producir datos que contengan información fuera de sus datos de entrenamiento? ¿Puede crear imágenes que sean completamente diferentes de las que se le dan?
Una forma de analizar eso es por lo que se llama la prueba de paradoja de cumpleaños. Esta prueba deriva su nombre de la implicación de que si pones a 23 -dos equipos de fútbol más un árbitro- personas al azar en una habitación, la posibilidad de que dos de ellos tengan el mismo cumpleaños es de más del 50%.
Este efecto ocurre porque con 365 días al año, necesitas al menos un número de personas alrededor de la raíz cuadrada de eso para ver un cumpleaños duplicado. La paradoja del cumpleaños dice que para una distribución discreta que tiene soporte N, entonces un tamaño de muestra aleatorio de √N probablemente contendría un duplicado. ¿Qué significa eso? Déjame desglosarlo.
Si hay 365 días al año, entonces necesitas la raíz cuadrada de 365 personas, √365, para tener una probabilidad probable de que dos tengan los mismos cumpleaños, lo que significa unas 19 personas. Pero esto también funciona para el otro lado de la ecuación. Si no sabes el número de días en un año, puedes seleccionar un número fijo de personas y pedirles sus cumpleaños. Si hay dos personas con el mismo cumpleaños, puedes inferir el número de días en un año con una alta probabilidad en función del número de personas. Si tienes 22 personas en la habitación, entonces el número de días en un año es el cuadrado de 22…222– unos 484 días al año, una aproximación del número real de días en un año.
La misma prueba puede comprobar el tamaño de la distribución original de las imágenes generadas por un GAN. Si el resultado revela que un conjunto de imágenes K contiene duplicados con una probabilidad razonable, entonces puede sospechar que el número de imágenes originales es de aproximadamente K2. Por lo tanto, si una prueba muestra que es muy probable que encuentre un duplicado en un conjunto de 20 imágenes, entonces el tamaño del conjunto original de imágenes es de aproximadamente 400. Esta prueba se puede ejecutar seleccionando subconjuntos de imágenes y comprobando con qué frecuencia encontramos duplicados en estos subconjuntos. Si encontramos duplicados en más del 50 % de los subconjuntos de cierta longitud, podemos usar ese tamaño para nuestra aproximación.
Con esa prueba en la mano, los investigadores han demostrado que las imágenes generadas por los famosos GAN no generalizan más allá de lo que proporcionan los datos de entrenamiento. Ahora, lo que queda por probar es si los GAN se pueden mejorar para generalizar más allá de los datos de entrenamiento o si hay formas de generalizar más allá de las imágenes originales mediante el uso de otros métodos para mejorar el conjunto de datos de entrenamiento.
GANS Y MALA INTENCIÓN
Hay preocupaciones de que la gente pueda usar la técnica GAN con malas intenciones. * Con tanta atención a los medios falsos, podríamos enfrentarnos a una gama aún más amplia de ataques con datos falsos. “La preocupación es que estos métodos alcancen hasta el punto en que sea muy difícil discernir la verdad de la falsedad”, dijo Tim Hwang, quien anteriormente supervisó la política de IA en Google y ahora es director del Fondo de Ética y Gobernanza de Inteligencia Artificial, una organización que apoya la investigación ética de IA. “Podrías creer que eso acelera los problemas que ya tenemos”. *
A pesar de que esta técnica no puede crear imágenes fijas de alta calidad, los investigadores creen que la misma tecnología podría producir vídeos, juegos y realidad virtual. El trabajo para empezar a generar vídeos ya ha comenzado. Los investigadores también están utilizando una amplia gama de otros métodos de aprendizaje automático para generar datos falsos. En agosto de 2017, un grupo de investigadores de la Universidad de Washington apareció en los titulares cuando construyeron un sistema que podía poner palabras en la boca de Barack Obama en un vídeo. Una aplicación con esta técnica ya está en la App Store de Apple. * Los resultados no fueron completamente convincentes, pero el rápido progreso en el área de los GAN y otras técnicas apuntan a un futuro en el que se vuelve difícil para la gente diferenciar entre los vídeos reales y los generados. Algunos investigadores afirman que los GAN son solo otra herramienta como otras que se puede usar para el bien o el mal y que habrá más tecnología para averiguar si los vídeos e imágenes recién creados son reales.
No solo eso, sino que los investigadores han descubierto formas de usar GAN para generar audio que suena como una cosa para los humanos, pero otra para las máquinas. * Por ejemplo, puedes desarrollar un audio que suene a los humanos como “¿Hola, cómo estás?” y a las máquinas, “Alexa, cómprame un trago”. O, audio que suena como una sinfonía de Bach para un ser humano, pero para la máquina, suena como “Alexa, ve a este sitio web”.
El futuro tiene un potencial ilimitado. Los medios digitales pueden superar a los medios analógicos a finales de esta década. Estamos empezando a ver ejemplos de esto con empresas como Synthesia. * Otros ejemplos de medios digitales se encuentran con Imma, un modelo de Instagram que es completamente generado por ordenadores y tiene alrededor de 350 mil seguidores. * No será sorprendente ver más y más medios digitales en el mundo a medida que el costo de crear dicho contenido baje y pueden ser cualquier cosa que sus creadores quieran.
Los datos son el nuevo petróleo
- ¿Cómo se creó ImageNet?
- ¿Qué es ImageNet?
- ¿Cómo creó Fei-Fei Li ImageNet?
Los datos son el nuevo aceite. Es valioso, pero si no se refina, realmente no se puede usar. Tiene que convertirse en gas, plástico, productos químicos, etc. para crear una entidad valiosa que impulse una actividad rentable; por lo tanto, los datos deben desglosarse y analizarse para que tengan valor.Clive Humby*
Los datos son clave para el aprendizaje profundo, y uno de los conjuntos de datos más importantes, ImageNet, creado por Fei-Fei Li, marcó el comienzo del campo. Se utiliza para entrenar redes neuronales, así como para compararlas con otras.
El aprendizaje profundo es un campo revolucionario, pero para que funcione según lo previsto, requiere datos. * El término para estos grandes conjuntos de datos y el trabajo que los rodea es Big Data, que se refiere a la abundancia de datos digitales. Los datos son tan importantes para los algoritmos de aprendizaje profundo como la arquitectura de la propia red, el software. Adquirir y limpiar los datos es uno de los aspectos más valiosos del trabajo. Sin datos, las redes neuronales no pueden aprender. *
La mayoría de las veces, los investigadores pueden usar los datos que se les dan directamente, pero hay muchos casos en los que los datos no están limpios. Eso significa que no se puede usar directamente para entrenar la red neuronal porque contiene datos que no son representativos de lo que el algoritmo quiere clasificar. Tal vez contenga datos malos, como imágenes en blanco y negro, cuando quieres crear una red neuronal para localizar gatos en imágenes de colores. Otro problema es cuando los datos no son apropiados. Por ejemplo, cuando quieres clasificar imágenes de personas como masculinas o femeninas. Puede haber imágenes sin la etiqueta necesaria o imágenes que tengan la información dañada con palabras mal escritas como “ale” en lugar de “masculino”. Aunque estos pueden parecer escenarios locos, suceden todo el tiempo. Manejar estos problemas y limpiar los datos se conoce como la reorganización de datos.
Los investigadores a veces también tienen que solucionar problemas con la forma en que se representan los datos. En algunos lugares, los datos pueden expresarse de una manera, y en otros los mismos datos se pueden describir de una manera completamente diferente. Por ejemplo, una enfermedad como la diabetes podría clasificarse con un cierto número (3) en una base de datos y (5) en otra. Esta es una de las razones del considerable esfuerzo en las industrias para crear estándares para compartir datos más fácilmente. Por ejemplo, Fast Healthcare Interoperability Resources (FHIR) fue creado por la organización internacional de salud, Health Level Seven International, para crear estándares para el intercambio de registros de salud electrónicos.
Estandarizar los datos es esencial, pero seleccionar la entrada correcta también es importante porque el algoritmo se crea en base a los datos. * Y elegir esos datos no es fácil. Uno de los problemas que pueden ocurrir al seleccionar datos es que pueden estar sesgados de alguna manera, creando un problema conocido como sesgo de selección. Eso significa que los datos utilizados para entrenar el algoritmo no representan necesariamente todo el espacio de posibilidades. El dicho en la industria es: “Lárdete, basura fuera”. Eso significa que si los datos introducidos en el sistema no son correctos, entonces el modelo no será preciso.
IMAGENET
Fei-Fei Li, que fue directora del Laboratorio de Inteligencia Artificial de Stanford y también la Científica Jefe de IA/ML en Google Cloud, pudo ver que los datos eran esenciales para el desarrollo de algoritmos de aprendizaje automático desde el principio,* antes que muchos de sus colegas.

Li se dio cuenta de que para hacer mejores algoritmos y redes neuronales más eficientes, se necesitaban más y mejores datos y que los mejores algoritmos no vendrían sin esos datos. En ese momento, los mejores algoritmos podían funcionar bien con los datos con los que fueron entrenados y probados, que eran muy limitados y no representaban el mundo real. Se dio cuenta de que para que los algoritmos funcionaran bien, los datos debían parecerse a la actualidad. “Decidimos que queríamos hacer algo que no tenía precedentes en la historia”, dijo Li, refiriéndose a un pequeño equipo que inicialmente trabajaba con ella. “Vamos a trazar todo el mundo de los objetos”.
Para resolver el problema, Li construyó uno de los conjuntos de datos más extensos para el aprendizaje profundo hasta la fecha, ImageNet. Se creó el conjunto de datos, y el documento que describe el trabajo se publicó en 2009 en una de las principales conferencias de visión por ordenador, Visión por Ordenador y Reconocimiento de Patrones (CVPR), en Miami, Florida. El conjunto de datos fue muy útil para los investigadores y, debido a eso, se hizo cada vez más famoso, proporcionando el punto de referencia para una de las competiciones anuales de aprendizaje profundo más importantes, que probó y entrenó algoritmos para identificar objetos con la tasa de error más baja.ImageNet se convirtió en el conjunto de datos más importante en el campo de la visión por ordenador durante una década y también ayudó a aumentar la precisión de los algoritmos que clasificaban los objetos en el mundo real. En solo siete años, la precisión de los algoritmos ganadores en la clasificación de objetos en imágenes aumentó del 72 % a casi el 98 %, superando la capacidad humana promedio.
Pero ImageNet no fue el éxito de la noche a la mañana que muchos imaginan. Se necesitó mucho sudor por parte de Li, comenzando cuando enseñó en la Universidad de Illinois Urbana-Champaign. Estaba lidiando con problemas que muchos otros investigadores compartían. La mayoría de los algoritmos estaban sobreentrenando el conjunto de datos que se les daba, lo que hacía incapaces de generalizar más allá de él. El problema era que la mayoría de los datos presentados a estos algoritmos no contenían muchos ejemplos, por lo que no tenían suficiente información sobre todos los casos de uso para que los modelos funcionaran en el mundo real. Sin embargo, se dio cuenta de que si generaba un conjunto de datos que era tan complejo como la realidad, entonces los modelos deberían funcionar mejor.
Es más fácil identificar a un perro si ves mil fotos de diferentes perros, en diferentes ángulos de cámara y en condiciones de iluminación, que si solo ves cinco fotos de perros. De hecho, es una regla general bien conocida que los algoritmos puedan extraer las características correctas de las imágenes si hay alrededor de 1000 imágenes para un determinado tipo de objeto.
Li comenzó a buscar otros intentos para crear una representación del mundo real, y se encontró con un proyecto, WordNet, creado por el profesor George Miller. WordNet era un conjunto de datos con una estructura jerárquica del idioma inglés. Se parecía a un diccionario, pero en lugar de tener una explicación para cada palabra, tenía una relación con otras palabras. Por ejemplo, la palabra “mono” está debajo de la palabra “primate”, que a su vez está debajo de la palabra “mamum”. De esta manera, el conjunto de datos contenía la relación de todas las palabras, entre otras.
Después de estudiar y aprender sobre WordNet, Li se reunió con la profesora Christiane Fellbaum, que trabajó con Miller en WordNet. Le dio a Li la idea de añadir una imagen y asociarla a cada palabra, creando un nuevo conjunto de datos jerárquico basado en imágenes en lugar de palabras. Li amplió la idea: en lugar de añadir una imagen por palabra, añadió muchas imágenes por palabra.
Como profesora asistente en Princeton, creó un equipo para abordar el proyecto ImageNet. La primera idea de Li fue contratar a los estudiantes para que encontraran imágenes y las añadieran a ImageNet manualmente. Pero se dio cuenta de que se volvería demasiado caro y les llevaría demasiado tiempo terminar el proyecto. Según sus estimaciones, le llevaría un siglo completar el trabajo, por lo que cambió de estrategia. En su lugar, decidió obtener las imágenes de Internet. Podía escribir algoritmos para encontrar las imágenes, y los humanos elegirían las correctas. Después de meses trabajando en esta idea, descubrió que el problema con esta estrategia era que las imágenes elegidas estaban limitadas a los algoritmos que eligían las imágenes. Inesperadamente, la solución llegó cuando Li estaba hablando con uno de sus estudiantes de posgrado, quien mencionó un servicio que permite a los humanos en cualquier parte del mundo completar pequeñas tareas en línea de forma muy barata. Con Amazon Mechanical Turk, encontró una manera de escalar y hacer que miles de personas encuentren las imágenes adecuadas por no demasiado dinero.
Amazon Mechanical Turk fue la solución, pero todavía existía un problema. No todos los trabajadores hablaban inglés como lengua materna, por lo que hubo problemas con imágenes específicas y las palabras asociadas con ellas. Algunas palabras eran más difíciles de identificar para estos trabajadores remotos. No solo eso, sino que había palabras como “babuin” que confundían a los trabajadores: no sabían exactamente qué imágenes representaban la palabra. Por lo tanto, su equipo creó un algoritmo simple para averiguar cuántas personas tenían que mirar cada imagen para una palabra determinada. Las palabras que eran más complejas como “babuin” requerían que más personas revisaran las imágenes, y las palabras más simples como “gato” solo necesitaban unas pocas personas.
Con Mechanical Turk, la creación de ImageNet tardó menos de tres años, mucho menos que la estimación inicial con solo estudiantes universitarios. El conjunto de datos resultante tenía alrededor de 3 millones de imágenes separadas en unas 5.000 “palabras”. Sin embargo, la gente no se impresionó con su trabajo o conjunto de datos, porque no creían que los datos cada vez más refinados condujeran a mejores algoritmos. Pero la mayoría de las opiniones de estos investigadores estaban a punto de cambiar.
EL DESAFÍO DE LA IMAGEN
Para demostrar su punto de vista, Li tuvo que demostrar que su conjunto de datos conducía a mejores algoritmos. Para lograrlo, tuvo la idea de crear un desafío basado en el conjunto de datos para mostrar que los algoritmos que lo utilizan tendrían un mejor rendimiento en general. Es decir, tuvo que hacer que otros entrenaran sus algoritmos con su conjunto de datos para demostrar que de hecho podrían funcionar mejor que los modelos que no usaban su conjunto de datos.
El mismo año que publicó el artículo en CVPR, se puso en contacto con un investigador llamado Alex Berg y sugirió que trabajaran juntos para publicar artículos para mostrar que los algoritmos que utilizan el conjunto de datos podrían averiguar si las imágenes contenían objetos o animales particulares y dónde se encontraban en la imagen. En 2010 y 2011, publicaron cinco artículos utilizando ImageNet. * El primero se convirtió en el punto de referencia de cómo se desempeñarían los algoritmos en estas imágenes. Para convertirlo en el punto de referencia para otros algoritmos, Li se puso en contacto con el equipo que apoyaba uno de los conjuntos de datos y estándares de referencia de reconocimiento de imágenes más conocidos, PASCAL VOC. Acordaron trabajar con Li y agregaron ImageNet como punto de referencia para su competencia. La competencia utilizó un conjunto de datos llamado PASCAL que solo tenía 20 clases de imágenes. En comparación, ImageNet tenía alrededor de 5.000 clases.
Como predijo Li, los algoritmos que se entrenaron utilizando el conjunto de datos de ImageNet funcionaron cada vez mejor a medida que la competencia continuaba. Los investigadores aprendieron que los algoritmos comenzaron a funcionar mejor para otros conjuntos de datos cuando los modelos se entrenaron por primera vez usando ImageNet y luego se ajustaron para otra tarea. Una discusión detallada sobre cómo funcionó esto para el cáncer de piel se encuentra en una sección posterior.
En 2012 se produjo un gran avance. El creador del aprendizaje profundo, Geoffrey Hinton, junto con Ilya Sutskever y Alex Krizhevsky presentó una arquitectura de red neuronal de convolucional profunda llamada AlexNet, que todavía se utiliza en la investigación hasta el día de hoy, “que venció al campo con un enorme margen de 10,8 puntos porcentuales”. * Eso marcó el comienzo del auge del aprendizaje profundo, lo que no habría sucedido sin ImageNet.
ImageNet se convirtió en el conjunto de datos de referencia para la revolución del aprendizaje profundo y, más específicamente, el de las redes neuronales de convolución (CNN) lideradas por Hinton.ImageNet no solo dirigió la revolución del aprendizaje profundo, sino que también estableció un precedente para otros conjuntos de datos. Desde su creación, se introdujeron decenas de nuevos conjuntos de datos con datos más abundantes y una clasificación más precisa. Ahora, permiten a los investigadores crear mejores modelos. No solo eso, sino que los laboratorios de investigación se han centrado en la publicación y el mantenimiento de nuevos conjuntos de datos para otros campos, como la traducción de textos y datos médicos.
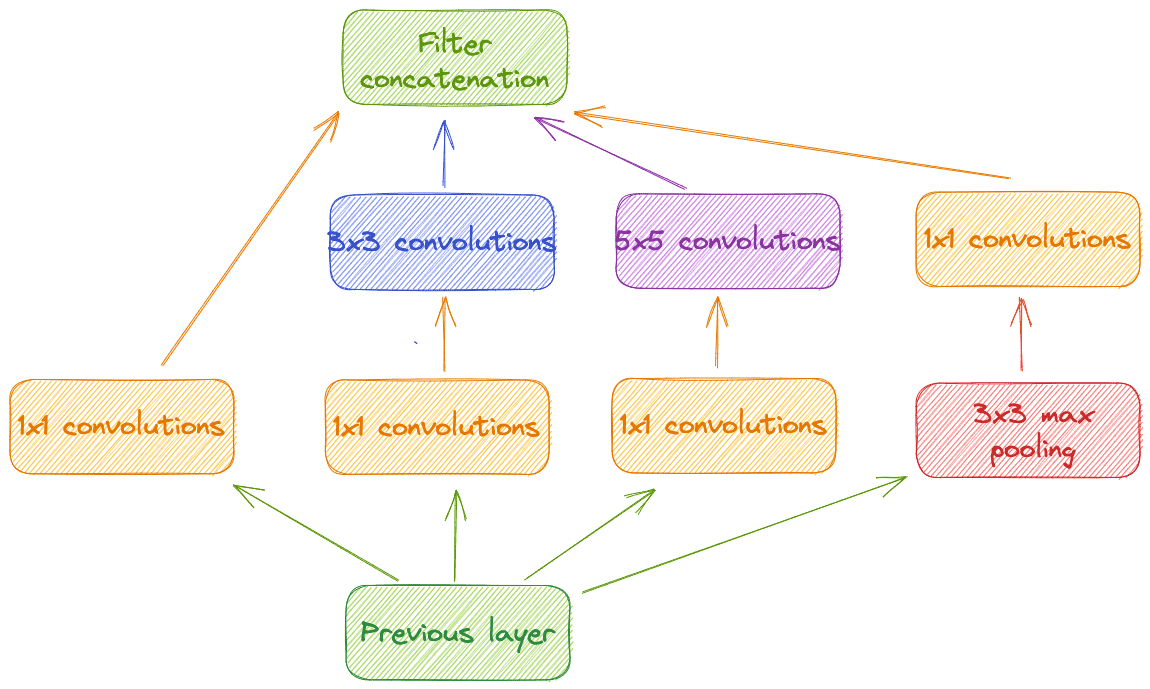
En 2015, Google lanzó una nueva red neuronal convolucional llamada Inception o GoogleNet. * Contenía menos capas que las redes neuronales de mayor rendimiento, pero funcionó mejor. En lugar de añadir un filtro por capa, Google añadió un módulo de inicio, que incluye algunos filtros que se ejecutan en paralelo. Mostró una vez más que la arquitectura de las redes neuronales es importante.
ImageNet se considera resuelto, alcanzando una tasa de error inferior a la humana promedio y logrando un rendimiento sobrehumano para averiguar si una imagen contiene un objeto y qué tipo de objeto es. Después de casi una década, la competencia para entrenar y probar modelos en ImageNet. Li intentó eliminar el conjunto de datos de Internet, pero las grandes empresas como Facebook retrocedieron ya que lo usaron como punto de referencia.
Pero desde el final de la competencia ImageNet, se han creado muchos otros conjuntos de datos basados en millones de imágenes, clips de voz y fragmentos de texto introducidos y compartidos en sus plataformas todos los días. La gente a veces da por sentado que estos conjuntos de datos, que son intensivos en recopilar, ensamblar y examinar, son gratuitos. Estar abierto y libre de usar fue un principio original de ImageNet que sobrevivirá al desafío y probablemente incluso al conjunto de datos. “Una cosa que ImageNet cambió en el campo de la IA es que de repente la gente se dio cuenta de que el trabajo ingloso de hacer un conjunto de datos estaba en el centro de la investigación de IA”, dijo Li. “La gente realmente reconoce la importancia del conjunto de datos en el centro de la investigación tanto como en los algoritmos”.
Privacidad de datos
Argumentar que no te importa el derecho a la privacidad porque no tienes nada que ocultar no es diferente a decir que no te importa la libertad de expresión porque no tienes nada que decir.Edward Snowden*
En 2014, Tim recibió una solicitud en su aplicación de Facebook para hacer un cuestionario de personalidad llamado “Esta es tu vida digital”. Le ofrecieron una pequeña cantidad de dinero y tuvo que responder solo algunas preguntas sobre su personalidad. Tim estaba muy emocionado de conseguir dinero para esta tarea aparentemente fácil e inofensiva, así que rápidamente aceptó la invitación. A los cinco minutos de recibir la solicitud en su teléfono, Tim inició sesión en la aplicación, dando a la empresa a cargo del cuestionario acceso a su perfil público y a todos los perfiles públicos de sus amigos. Completó el cuestionario en 10 minutos. Un centro de investigación del Reino Unido recopiló los datos, y Tim continuó con su día mundano como empleado de abogados en uno de los bufetes de abogados más grandes de Pensilvania.
Lo que Tim no sabía era que acababa de compartir sus datos y los de todos sus amigos con Cambridge Analytica. Esta empresa utilizó los datos de Tim y los datos de otros 50 millones de personas para orientar los anuncios políticos basados en sus perfiles psicográficos. A diferencia de la información demográfica como la edad, los ingresos y el género, los perfiles psicográficos explican por qué las personas hacen compras. El uso de datos personales a tal escala hizo de este esquema, en el que Tim participó pasivamente, uno de los mayores escándalos políticos hasta la fecha.
Los datos se han convertido en una parte esencial de los algoritmos de aprendizaje profundo. * Las grandes corporaciones ahora almacenan muchos datos de sus usuarios porque eso se ha convertido en una parte central de la construcción de mejores modelos para sus algoritmos y, a su vez, de la mejora de sus productos. Para Google, es esencial tener los datos de los usuarios para desarrollar los mejores algoritmos de búsqueda. Pero a medida que las empresas recopilan y mantienen todos estos datos, se convierte en una responsabilidad para ellas. Si una persona tiene fotos en su teléfono que no quiere que nadie más vea, y si Apple o Google recopila esas fotos, sus empleados podrían tener acceso a ellas y abusar de los datos. Incluso si estas empresas protegen contra que sus propios empleados tengan acceso a los datos, podría producirse una violación de la privacidad, permitiendo a los piratas informáticos acceder a los datos privados de las personas.
Los hacks que resultan en la publicación de los datos de los usuarios son muy comunes. Cada año, parece que el número de personas afectadas por un hackeo determinado aumenta. Un hackeo de Yahoo comprometió las cuentas de 3 mil millones de personas. * Por lo tanto, todos los datos que estas empresas tienen sobre sus usuarios se convierten en una carga. En otras ocasiones, los datos se dan a los investigadores, esperando lo mejor de sus intenciones. Pero los investigadores no siempre son sensibles al manejar datos. Ese fue el caso del escándalo de Cambridge Analytica. En ese caso, Facebook proporcionó a los investigadores acceso a información sobre los usuarios y sus amigos que estaba principalmente en sus perfiles públicos, incluidos los nombres, cumpleaños e intereses de las personas. * Esta empresa privada luego utilizó los datos y los vendió a campañas políticas para dirigirse a las personas con anuncios personalizados basados en su información.
PRIVACIDAD DIFERENCIAL
La privacidad diferencial es una forma de obtener estadísticas de un conjunto de datos de muchas personas sin revelar qué datos proporcionó cada persona.
Mantener datos confidenciales o dar datos directamente a los investigadores para crear mejores algoritmos es peligroso. Los datos personales deben ser privados y seguir siendo así. Ya en 2006, los investigadores de Microsoft estaban preocupados por la privacidad de los datos de los usuarios y crearon una técnica innovadora llamada privacidad diferencial, pero nunca la usaron en sus productos. Diez años después, Apple lanzó productos en el iPhone utilizando este mismo método.
Cargando imagen…
Figura: Cómo funciona la privacidad diferencial.
Apple implementa una de las versiones más privadas de la privacidad diferencial, llamada modelo local. Añade ruido a los datos directamente en el dispositivo del usuario antes de enviarlos a los servidores de Apple. De esa manera, Apple nunca toca los datos verdaderos del usuario, lo que impide que nadie que no sea el usuario tenga acceso a ellos. Los investigadores pueden analizar las tendencias de los datos de las personas, pero nunca pueden acceder a los detalles. *
La privacidad diferencial no se limita a hacer que los datos de los usuarios sean anónimos. Permite a las empresas recopilar datos de grandes conjuntos de datos, con una prueba matemática de que nadie puede aprender sobre un solo individuo. *
Imagina que una empresa quisiera recopilar la altura media de sus usuarios. Anna mide 5 pies y 6 pulgadas, Bob mide 5 pies y 8 pulgadas y Clark mide 5 pies y 5 pulgadas. En lugar de recopilar la altura individualmente de cada usuario, Apple recopila la altura más o menos un número aleatorio. Por lo tanto, recogería 5 pies 6 pulgadas más 1 pulgada para Anna, 5 pies 8 pulgadas más 2 pulgadas para Bob, y 5 pies 5 pulgadas menos 3 pulgadas para Clark, lo que equivale a 5 pies 7 pulgadas, 5 pies 10 pulgadas y 5 pies 2 pulgadas, respectivamente. Apple promedia estas alturas sin los nombres de los usuarios.
La altura media de sus usuarios sería la misma antes y después de añadir el ruido: 5 pies y 6 pulgadas. Pero Apple no recopilaría la altura real de nadie, y su información individual permanece en secreto. Eso permite a Apple y a otras empresas crear modelos inteligentes sin recopilar información personal de sus usuarios, protegiendo así su privacidad. La misma técnica podría producir modelos sobre imágenes en los teléfonos de las personas y cualquier otra información.
La privacidad diferencial, o mantener los datos privados de los usuarios, es muy diferente de la anonimización. La anonimización no garantiza que la información que tiene el usuario, como una imagen, no se filtre o que el individuo no pueda rastrearse desde los datos. Un ejemplo es enviar un seudónimo del nombre de una persona, pero aún así transmitir su altura. La anonimización tiende a fallar. En 2007, Netflix publicó 10 millones de calificaciones de películas de sus espectadores para que los investigadores crearan un mejor algoritmo de recomendación. Solo publicaron calificaciones, eliminando todos los detalles de identificación. * Los investigadores, sin embargo, compararon estos datos con datos públicos en la base de datos de películas de Internet (IMDb). * Después de hacer coincidir los patrones de recomendaciones, añadieron los nombres de nuevo a los datos anónimos originales. Es por eso que la privacidad diferencial es esencial. Se utiliza para evitar que los datos del usuario se filtren de cualquier manera posible.
Esta cifra muestra el porcentaje de uso de cada emoji sobre el uso total de emojis para los países de habla inglesa y francesa. Los datos se recopilaron utilizando una privacidad diferencial. La distribución del uso de emojis en los países de habla inglesa difiere de la de los países de habla francesa. Eso podría revelar diferencias culturales subyacentes que se traducen en la forma en que cada cultura utiliza el lenguaje. En este caso, la frecuencia con la que usan cada emoji es interesante.
Apple comenzó a usar la privacidad diferencial para mejorar su teclado predictivo*, la búsqueda de Spotlight y la aplicación Fotos. Fue capaz de avanzar en estos productos sin obtener datos específicos del usuario. Para Apple, la privacidad es un principio fundamental. Tim Cook, CEO de Apple, ha pedido una y otra vez una mejor regulación de la privacidad de los datos. * Los mismos datos y algoritmos que se pueden utilizar para mejorar la vida de las personas pueden ser utilizados como un arma por los malos actores.
El teclado predictivo de Apple, con los datos que recopiló con privacidad diferencial, ayuda a los usuarios ofreciendo la siguiente palabra que debería estar en el texto en función de sus modelos. Apple también ha podido crear modelos para lo que hay dentro de las imágenes de las personas en sus iPhones sin tener datos reales de los usuarios. Es posible que los usuarios busquen artículos específicos como “montañas”, “sillas” y “coches” en sus fotos. Y todo eso lo sirven modelos desarrollados utilizando privacidad diferencial. Apple no es el único que utiliza privacidad diferencial en sus productos. En 2014, Google lanzó un sistema para su navegador web Chrome para averiguar las preferencias de los usuarios sin invadir su privacidad.
Pero Google también ha estado trabajando con otras tecnologías para producir mejores modelos mientras continúa manteniendo la privacidad de los datos de los usuarios.
APRENDIZAJE FEDERADO
Google desarrolló otra técnica llamada aprendizaje federado. * En lugar de recopilar estadísticas sobre los usuarios, Google desarrolló un modelo interno y luego lo implementó en cada uno de los ordenadores, teléfonos y aplicaciones de los usuarios. Luego, el modelo se entrena en función de los datos generados por el usuario o que ya están presentes.
Por ejemplo, si Google quiere crear una red neuronal para identificar objetos en imágenes y tiene un modelo de cómo se ven los “gatos”, pero no cómo se ven los “perros”, entonces la red neuronal se envía al teléfono de un usuario que contiene muchas imágenes de perros. A partir de eso, aprende cómo son los perros, actualizando sus pesas. Luego, resume todos los cambios en el modelo como una pequeña actualización enfocada. La actualización se envía a la nube, donde se promedia con las actualizaciones de otros usuarios para mejorar el modelo compartido. Los datos de todos avanzan en el modelo.
El aprendizaje federado* funciona sin necesidad de almacenar los datos de los usuarios en la nube, pero Google no se detiene allí. Han desarrollado un protocolo de agregación seguro que utiliza técnicas criptográficas para que solo puedan descifrar la actualización promedio si cientos o miles de usuarios han participado. * Eso garantiza que ninguna actualización individual del teléfono se pueda inspeccionar antes de promediarlo con los datos de otros usuarios, protegiendo así la privacidad de las personas. Google ya utiliza esta técnica en algunos de sus productos, incluido el teclado de Google que predice lo que escribirán los usuarios. El producto es muy adecuado para este método, ya que los usuarios escriben mucha información confidencial en su teléfono. La técnica mantiene esos datos privados.
Este campo es relativamente nuevo, pero está claro que estas empresas no necesitan conservar los datos de los usuarios para crear mejores y más refinados algoritmos de aprendizaje profundo. En los próximos años, se producirán más hacks, y los datos de los usuarios que se han almacenado para mejorar estos modelos se compartirán con hackers y otras partes. Pero eso no tiene por qué ser la norma. No es necesario negociar la privacidad para obtener mejores modelos de aprendizaje automático. Ambos pueden coexistir.
Procesadores de aprendizaje profundo
Lo que no se ha realizado completamente es que la Ley de Moore no fue el primero, sino el quinto paradigma que trajo un crecimiento exponencial a las computadoras. Teníamos calculadoras electromecánicas, ordenadores basados en relés, tubos de vacío y transistores. Cada vez que un paradigma se agotó, otro se hizo cargo.Ray Kurzweil*
El poder del aprendizaje profundo depende del diseño y del entrenamiento de las redes neuronales subyacentes. En los últimos años, las redes neuronales se han complicado, a menudo conteniendo cientos de capas. Esto impone mayores requisitos computacionales, lo que provoca un auge de la inversión en nuevos microprocesadores especializados en este campo. El líder de la industria Nvidia gana al menos 600 millones de dólares por trimestre por vender sus procesadores a centros de datos y empresas como Amazon, Facebook y Microsoft.
Solo Facebook ejecuta redes neuronales convolucionales al menos 2 mil millones de veces al día. Ese es solo un ejemplo de lo intensivas que son las necesidades informáticas de estos procesadores. Los coches Tesla con piloto automático habilitado también necesitan suficiente potencia computacional para ejecutar su software. Para hacerlo, los coches Tesla necesitan un superprocesador: una unidad de procesamiento gráfico (GPU).
La mayoría de los ordenadores que la gente usa hoy en día, incluidos los teléfonos inteligentes, contienen una unidad central de procesamiento (CPU). Esta es la parte de la máquina donde se realiza todo el cálculo, es decir, donde reside el cerebro del ordenador. Una GPU es similar a una CPU porque también está hecha de circuitos electrónicos, pero se especializa en acelerar la creación de imágenes en videojuegos y otras aplicaciones. Pero las mismas operaciones que los juegos necesitan para aparecer en las pantallas de las personas también se utilizan para entrenar redes neuronales y ejecutarlas en el mundo real. Por lo tanto, las GPU son mucho más eficientes para estas tareas que las CPU. Debido a que la mayor parte del cálculo necesario es en forma de redes neuronales, Tesla agregó GPU a sus coches para que puedan conducir por las calles.
Nvidia, una empresa fundada por el inmigrante taiwanés Jensen Huang*, produce la mayoría de las GPU que utilizan las empresas, incluidos Tesla, Mercedes y Audi. * Tesla utiliza el Nvidia Drive PX2, que está diseñado para coches autónomos. * El procesador Nvidia Drive tiene un conjunto de instrucciones especializadas que acelera el rendimiento de las redes neuronales en tiempo de ejecución y puede calcular 8 TFLOPS, lo que significa 8 billones de operaciones matemáticas de coma flotante por segundo.
El TFLOP (tril millones de operaciones matemáticas de coma flotante por segundo) es una unidad para medir el rendimiento de los chips utilizados para comparar la potencia que tiene un determinado chip para procesar redes neuronales.
La creciente demanda de productos de Nvidia ha sobrealimentado el crecimiento de la empresa. * De enero de 2016 a agosto de 2021, las acciones se han disparado de 7 a 220 $. * La mayor parte del dinero que Nvidia gana hoy en día proviene de la industria de los juegos, pero a pesar de que las aplicaciones automáticas son un nuevo campo para ellos, ya representan 576 millones de dólares anuales o el 2 % de sus ingresos. Y la industria de la conducción autónoma acaba de empezar. *
Los videojuegos eran el volante, o la aplicación asesina como se llama en Silicon Valley, para la empresa. Tienen un volumen de ventas potencial increíblemente alto y, al mismo tiempo, representan uno de los problemas más difíciles desde el punto de vista computacional. Los videojuegos ayudaron a Nvidia a entrar en el mercado de las GPU, financiando la I+D para crear procesadores más potentes.
La cantidad de computación que las GPU, al igual que las CPU, pueden manejar ha seguido una curva exponencial a lo largo de los años. La Ley de Moore es una observación de que el número de transistores, el elemento básico de una CPU, se dubla aproximadamente cada dos años. *
Gordon Moore, cofundador de Intel, una de las empresas más importantes que desarrollan microprocesadores, creó esta ley de mejora. La potencia computacional de las CPU ha aumentado exponencialmente. De la misma manera, el número de operaciones, el TFLOPS, que las GPU pueden procesar ha seguido la misma curva exponencial, adhiriéndose a la Ley de Moore.
Pero incluso con la creciente capacidad de las GPU, era necesario un hardware más especializado desarrollado específicamente para el aprendizaje profundo. A medida que el aprendizaje profundo se utilizaba cada vez más, la demanda de unidades de procesamiento adaptadas a la técnica superó lo que las GPU podían proporcionar. Por lo tanto, las grandes corporaciones comenzaron a desarrollar equipos diseñados específicamente para el aprendizaje profundo. Y Google era una de esas empresas. Cuando Google concluyó que necesitaba el doble de CPUs que tenían en sus centros de datos para apoyar sus modelos de aprendizaje profundo para el reconocimiento de voz, creó un grupo internamente para desarrollar hardware destinado a procesar las redes neuronales de manera más eficiente. Para implementar los modelos de la empresa, necesitaba desarrollar un procesador especializado.
UNIDAD DE PROCESAMIENTO DE TENSORES
En su búsqueda por hacer un procesador más eficiente para las redes neuronales, Google desarrolló lo que se llama una unidad de procesamiento de tensores (TPU). El nombre proviene del hecho de que el software utiliza el lenguaje TensorFlow, del que hablamos anteriormente. Los cálculos como la multiplicación o el álgebra lineal que manejan los TPU no necesitan tanta precisión matemática como el procesamiento de vídeo que hacen las GPU, lo que significa que los TPU necesitan menos recursos y pueden hacer muchos más cálculos por segundo.
Google lanzó su primer TPU en 2016. Esta versión de su procesador de aprendizaje profundo estaba dirigida únicamente a la inferencia, lo que significa que solo se centraba en ejecutar redes que ya habían sido entrenadas. La inferencia funciona de tal manera que si ya hay un modelo entrenado, entonces ese modelo puede ejecutarse con un solo chip. Pero para entrenar un modelo, necesitas varios chips para obtener un cambio rápido, lo que evita que tus programadores esperen mucho tiempo para ver si funciona.
Ese es un problema mucho más difícil de resolver porque necesitas interconectar los chips y asegurarte de que estén sincronizados y comunicando los mensajes apropiados. Por lo tanto, Google decidió lanzar una segunda versión de TPU un año después con la función añadida de que los desarrolladores podrían entrenar sus modelos en estos chips. Y un año después, Google lanzó su tercera generación de TPU que podían procesar ocho veces más que la versión anterior y tenían refrigeración líquida para abordar su intenso uso de energía. *
Para tener una idea de lo potentes que son estos chips de procesamiento, un solo TPU de segunda generación puede funcionar alrededor de 120 TFLOPS, o 200 veces los cálculos de un solo iPhone. * Las empresas están luchando para producir hardware que pueda realizar el procesamiento más rápido para las redes neuronales. Después de que Google anunciara sus unidades de TPU de segunda generación, Nvidia anunció su nueva GPU llamada Nvidia Volta, que ofrece alrededor de 100 TFLOPS. *
Pero aún así, los TPU son entre 15 y 30 veces más rápidos que las GPU, lo que permite a los desarrolladores entrenar sus modelos mucho más rápido que con los procesadores antiguos. No solo eso, sino que los TPU son mucho más eficientes energéticamente en comparación con las GPU, lo que permite a Google ahorrar mucho dinero en electricidad. Google está invirtiendo mucho en el aprendizaje profundo y los compiladores relacionados, que es la parte de la computadora que convierte el código legible por humanos en código legible por máquina. Eso significa que necesita mejoras en el espacio físico (hardware) y digital (software). Este campo de investigación y desarrollo es tan grande que Google tiene divisiones enteras dedicadas a hacer mejoras en diferentes partes de la tubería de su desarrollo.
Google no es el único gigante que trabaja en su propio hardware especializado para el aprendizaje profundo. El último procesador del iPhone 12 también tiene una unidad especializada llamada chip biónico A14. * Esta pequeña unidad electrónica puede procesar hasta 0,6 TFLOPS, o 600 mil millones de operaciones de coma flotante por segundo. Parte de ese poder de procesamiento se utiliza para el reconocimiento facial al desbloquear el teléfono, alimentando FaceID. Tesla también ha desarrollado sus propios chips de procesamiento para ejecutar sus redes neuronales, mejorando su software de coche autónomo. * El último chip que Tesla desarrolló y lanzó puede procesar hasta 36 TFLOPS. *
El tamaño de las redes neuronales ha ido creciendo y, por lo tanto, la potencia de procesamiento necesaria para crear y ejecutar los modelos también ha aumentado. OpenAI publicó un estudio que mostró que la cantidad de computación utilizada en las carreras de entrenamiento de IA más grandes ha aumentado exponencialmente, duplicándose cada 3,5 meses. Y esperan que el mismo crecimiento continúe en los próximos cinco años. De 2012 a 2018, la cantidad de computación utilizada para entrenar estos modelos aumentó 300.000 veces. *
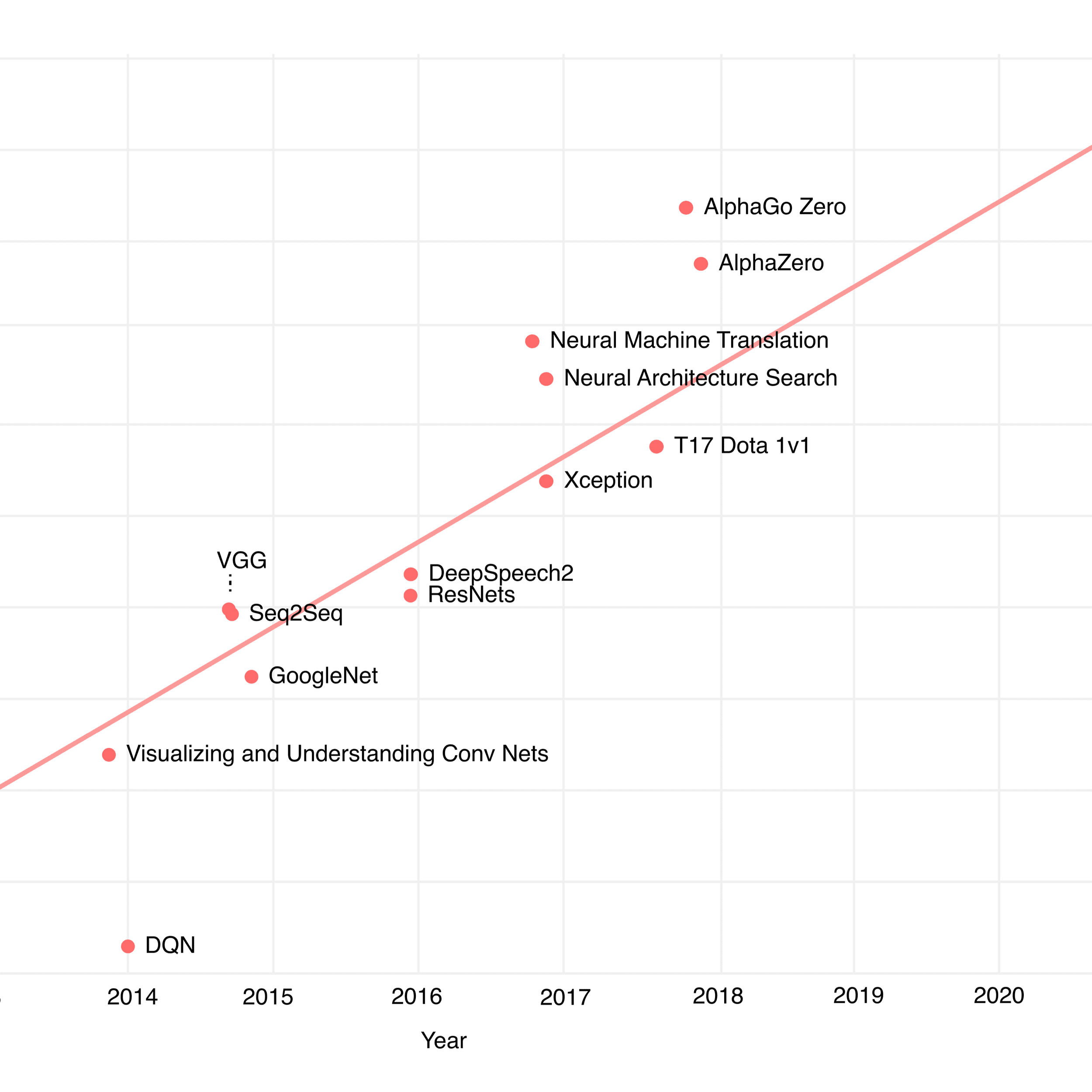
Este crecimiento tiene paralelos en el mundo biológico, en los que hay una clara correlación entre la capacidad cognitiva de los animales y el número de neuronas paliales o corticales. De ello debe seguir que el número de neuronas de una red neuronal artificial que simulan el cerebro de los animales debería afectar el rendimiento de estos modelos.
A medida que pasa el tiempo y aumenta la cantidad de computación utilizada para entrenar modelos de aprendizaje profundo, cada vez más empresas desarrollarán chips especializados para manejar el procesamiento, y un número cada vez mayor de aplicaciones utilizarán el aprendizaje profundo para lograr todo tipo de tareas.